从官网的这张经典图对iceberg的表格式就有了一个大致的映像。
总之iceberg表格式就从根本上就就是文件列表的组织规范,将一堆文件按照其规范进行读和写就能够保证逻辑上的表的数据读写正常。
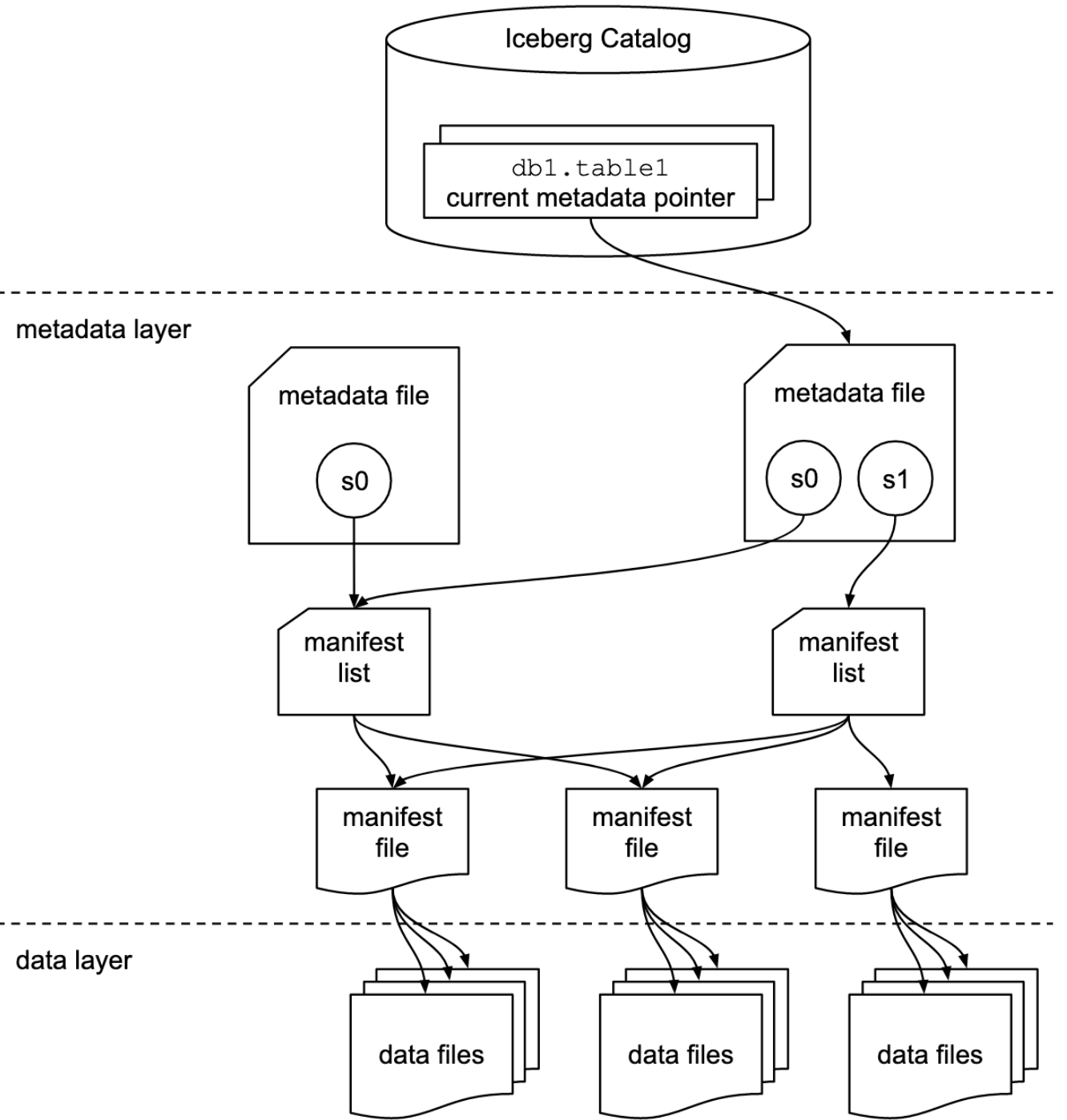
上图只说明了文件列表当中的分层结构以及文件的分类。底层的数据文件的格式并没有强制规定,可以是parquet、avro、orc,就是用来存储数据的一个文件格式,这里就不加介绍了。
iceberg表本身就是一种格式规范,具体到每个类型的文件metadata, snapshot, manifest都有自己的schema。iceberg每一层存储下一层文件的统计信息,方便查询。
Catalog
在大数据领域似乎已经成为一个标准规范了,catalog简单来说就是提供数据访问的入口。或者更加具体一些来讲,我们使用的数据服务一般都是有表这个概念的,catalog就是提供一个能力,即传入一张表的标记可以确定到唯一的表。
具体到iceberg就是,iceberg使用指定的TableIdentifier,然后定位到这张表的metadata file,也就是找到了这张表的实际存储位置。
至于catalog的实现方式则是多样的,只要具有上面提到的能力即可。比如
- REST服务
- JDBC
- Hive MetaStore
- Nessie:一个类似于git版本控制的数据库来追踪TableIdentifier和Table映射
metadata
metadata中包含了表的历史演进信息,例如schema的演进。同时每一个时刻表的状态都对应一个snapshot,这些snapshot也都记录在metadata当中。 这样选择不同的snapshot就可以查看对应时刻的表的状态了,实现时间旅行的能力。
详解参照metadata
snapshot
在metadata当中已经提到了,就是表示某一时刻的表状态。对iceberg表的每一次修改都会生成一个新的snapshot。
通过snapshot可以查到当时的完整的表数据。这是因为snapshot中记录了manifest list,通过这个文件可以追踪到当时的所有数据文件。
至于为什么是manifest文件的列表。这是因为快照某一时刻的数据是一个历史累计的结果。每一次的修改都会产生manifest文件,那么当然snapshot需要将达到当前状态的所有历史修改都记录下来,因此也就有了manifest list
详解参照snapshot
manifest
在数据文件的上一层,可以理解为记录数据文件元数据的文件。 manifest本身是一个avro格式的文件,记录了数据文件或者删除文件的列表,还记录了每个数据文件的分区信息、指标信息和跟踪信息等。
一个写数的过程中,可能产生多个数据文件以及多个manifest文件
- 修改操作会先删除,再新增数据。那么删除的数据文件,和新增数据的数据文件是需要不同的manifest来追踪的,是不能混用的
- 当一次修改写入的数据很大的时候,为了后续读取的性能,一般都会限制数据文件的大小,一次写数就可能产生多个数据文件
表的新数据写入只会增加新的manifest文件,一些schema级别的修改只会修改表的元数据,影响后续写入的新数据,对现有的数据snapshot、manifest和数据文件都没有影响。
data files
就是实际的数据存放的地方。因为这里不展开讲诉iceberg支持的数据文件格式,如parquet的具体规范,所以到是没有什么特别值得讲的。
不过需要注意的是,iceberg的数据文件是区分普通的数据文件和删除文件两类的,数据的修改是通过写删除文件和写数据文件来完成,不会修改已经存在的文件。
总结
通过上述的结构。通过表标识TableIdentifier,从catalog服务中获取到唯一的表,然后根据指定的快照版本/最新快照,可以一层一层的找到所有的数据文件,最终完成表的数据读取。
相对地,写数流程就是在写数过程中同步更新每一个层的元信息,在数据写完提交的时候将每一层的文件也一并提交。