原文链接:Bigtable: A Distributed Storage System for Structured Data
BigTable作用的对象和提供的能力为
- 结构化数据
- 大规模
- 灵活的伸缩能力
- 高性能
本文就是对BigTable数据模型的简单介绍,是如何为客户端提供对数据布局和格式进行动态控制的能力的。
BigTable不支持完成的关系数据模型,而是为客户端提供简单的数据模型,并允许客户端动态控制其布局和格式,推断底层存储中数据的局部性属性。
BigTable中的数据是通过row和column来进行索引的,可以是任意的字符串类型。在BigTable中,数据本身就被看作是未解释的字符串,尽管客户端经常将各种结构化、半结构化的序列化的结构作为数据。客户端可以通过schema来控制数据的位置。
数据模型
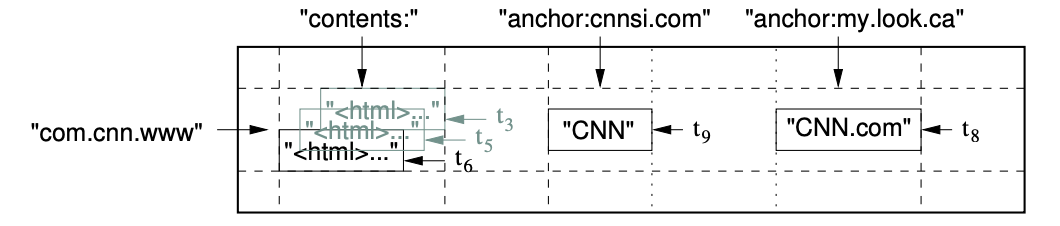
首先对BigTable进行一个定义,BigTable是一个稀疏的、分布式的、可持久化的多维度有序map。 使用row key, column key, timestamp key作为索引。value就是未解释的字节数组,也就是value的含义只有BigTable应用者知晓。
简单来说就是BigTable可以看作一个map,通过key可以确定唯一的value (row: string, column: string, timestamp: int64) → string。
下面对数据模型的介绍就以这个web page的存储作为示例。
row
row key是任意的字符串,当然再系统中是限制了64KB的上限,但是大多数情况下再10~100字节就够了。对一个row key的读写操作是原子的。 BigTable就是按照row key的字典顺序来维护数据的。并且会将一组row划分到一起作为一个分区,叫做tablet,是分布式和负载均衡的基础单位,分区的划分是动态控制的。因此,在同一个tablet中的row读取是非常高效的,通常只需要一次通信即可完成。利用这个特性,客户端在使用的时候可以让联系紧密的数据划分到一起,这样更好访问。例如使用url的反向url,可以使得相同域名的数据访问更加高效。
column family
column key是按照集合进行分组的,这些集合叫做column family,作为访问控制的基本单位。
column family中的数据具有相同的类型。column key带上column family的语法为family:qualifier。就像上图中的anchor就是一个column family。
timestamp
通过row key + column key定位到的一个cell是具有多个版本的数据的。这些版本是通过timestamp进行索引的。timestamp是由bigtable分配的64bit的整数,表示精确度为微秒的时间。
为了避免数据冲突,应用程序必须自己生成唯一的时间戳,并降序存储,这样就可以先读取最新版版本的数据了。同时为了避免数据的版本不断累积,还支持对数据的版本进行垃圾回收,bigtable在column family级别提供了两个设置来自动回收cell的版本,比如保留最新的n个版本,或者最久保留的时间。
BigTable搭建
BigTable的存储是基于GFS的,数据的存储格式是SSTable。其实这里就可以看出BigTable是一个村算分离的系统。
BigTable还依赖Chubby这个高可用、持久化的分布式锁服务。这里对chubby做一个简单的介绍。
chubby时使用paxos作为分布式共识算法,搭建的5节点的集群。chubby的命名空间由目录和文件组成,每个目录和文件都可以作为锁使用,并且对文件的读写都是原子的。chubby的client会缓存一个chubby文件的一致性数据,每个client都会与chubby服务维护一个session并定时刷新,当一个client的session过期它的锁也会全部释放。
BigTable使用chubby主要有以下几个作用
- 确保同时只有一个可用的master服务
- 存储BigTable的启动位置(后续介绍)
- 发现和终止tablet server
- 存储BigTable schema信息(每个tablet的column family)
- 存储访问控制列表 很明显的一个问题就是chubby不可用会导致BigTable的不可用。
实现
BigTable的实现分为三部分
- client库
- 一个master server
- 多个tablet server
master负责分配tablet给tablet server,检测tablet server的添加和过期,平衡tablet server的负载,对GFS中的文件进行垃圾回收,除此之外还处理schema的变更,例如table和column family的创建。
每个tablet server都管理一个tablet的集合,负责处理分配给它的tablet的读写请求,并且在tablets变大之后进行分片。由于存算分离,数据都在GFS上,tablet server本身并不存储任何数据,因为可以动态的伸缩,也只会涉及部分tablet的划分。一个table由一组tablets集合组成,每个tablet包含其row range的所有关联数据,随着table的数据的增长,table会自动划分tablet,每个tablet默认约100~200MB。
BigTable还有一个值得注意的设计是,虽然是一个单master的系统,但是BigTable的client并不会和master进行通信,而是直接和tablet server通信进行读写,因此在实践中,master的负载时比较低的。
结合chubby一起来看的话可以发现
- BigTable集群需要持久化的元数据是使用Chubby存储的。
- 集群的分布式锁、集群入口等信息也是chubby负责的。
- master主要是tablet的管理等运行时数据
table location
前面讲bigtable client不依赖master,就是通过table location的设计完成的。使用了类似B+树的三层结构来存储table的位置信息。
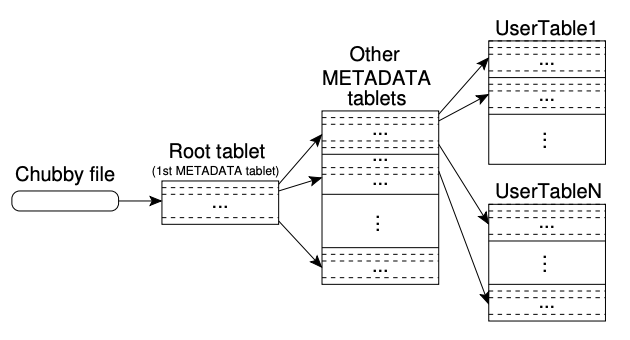
首先是chubby中存储了root tablet的位置,root tablet记录了特殊的名为METADATA表的所有tablets的位置。METADATA表的每个tablet包含了一组用户tablets的集合。 其中root tablet是METADATA表的第一个tablet,并且比较特殊,永远不会拆分,确保tablet位置的层次结构不会超过三层。
METADATA表中存储的是一个tablet所属的table的标识以及划分的row range的最后的row。METADATA的每个row存储的内存数据约1KB,依据最大128MB限制的tablet,这三层结构足够定位个tablet。
client查找一个tablet的位置的流程如下:
- 查询client缓存的tablet位置信息。若不存在或者缓存的位置信息不正确,则执行下一步。
- 递归向上查询tablet位置的层次结构 也就是说如果缓存为空的话,那么需要位置查询算法需要三次网络请求往返,包括一次chubby的读取请求。如果缓存的数据是旧的,那么位置查询算法可能需要六次网络往返。虽然位置信息存储在内存当中,不需要访问GFS,但是一般情况下还是会让client预读取tablet的位置来降低cost:每次读取METADATA表的时候都会读取多个tablet的元数据。
还会将次要信息存储在元数据表中,包括和每个tablet相关的所有事件日志,这些信息对调试和性能分析很有帮助。
client查询数据通常会指定tableName, row key, column family,column等信息。通过tableName + row key和metadata的三层结构就能够最终确定到本次查询的tablet所在的tablet server。
- 通过root tablet + tableName。获取到对应的Metadata tablet,这里存的一个表的元数据。及这个表下的所有tablet的元数据
- 通过row key在metadata tablet中找到所属的tablet。获取到所属的tablet server
- 请求对应的tablet server,通过row key + column family + column进行查询。
说是三层结构其实就是一个METADATA表,单独抽离了一个root tablet出来,并让chubby记录这个root tablet的位置。将METADATA表的信息存放在指定的路径,启动的时候读取到root tablet,再继续获取到其他的metadata tablet。最终可以获取到整个Bigtable中的所有tablet。
tablet分配
每个tablet同一时刻只会分配给一个tablet server。master会追踪所有存储的tablet server和tablet的分配信息,当然没有被分配的tablet也包括在内。当一个tablet未分配的时候,如果一个tablet server可用,那么master就会向这个tablet server发送一个tablet load请求来将tablet分配给这个tablet server。
tablet server启动的时候会在chubby当中创建并获取一个排它锁,也就是在特定的chubby目录下的唯一名的文件。master会监控这个目录来发现tablet server。当tablet server丢失排它锁之后就会停止提供tablet服务,比如网络分区等原因。只要启动时创建的文件还存在那么tablet server会就尝试重新获取排它锁,不存在了话tablet server就会杀死自己。而tablet server终止的时候就会尝试释放锁以便master能够重新分配它的tablets。
为啥使用chubby记录tablet server,又让master监控chubby来获取tablet server,而不是直接让master维护tablet server呢?
目前看下来如果直接让master记录tablet server,那么在tablet server和master之间又要维护心跳和状态。这套逻辑看着和chubby提供的分布式锁的能力是相同的,在上面的介绍中也正是按照分布式锁的方式确认tablet server的存活和下线的。就没有必要再开发一套类似的逻辑,直接复用chubby的能力即可。
master会定期访问每个tablet server获取它们锁的状态。如果tablet server上报其丢失锁或者尝试几次后也无法和tablet server进行通信,那么master尝试去chubby获取这个tablet server的server file,能够获取到就说明chubby存活而tablet server要么不存在要么和chubby通信存在问题,master直接认为这个tablet server无法继续提供服务,删除这个server file。删除之后,master就可以将这个server的tablets变为未分配的状态。要是master无法访问到chubby的话,那么它自己就会主动退出,避免集群中存在多个master。
master启动的时候需要先发现当前tablet的分配情况,按照以下步骤:
- master在chubby获取一个唯一的master锁,避免并发的master实例化。
- master扫瞄chubby的server目录来找到所有存活的tablet server
- 与每个tablet server通信获取已经分配给它们的tablet
- master扫描METADATA表获取tablets,找到未分配的则加入unassigned tablets集合,以便能够被分配。 一个复杂的问题在于,如果METADATA的tablet没有被分配,那么METADATA的表就没有办法进行扫描,因此在开始第四步的扫描之前,若是在第三步没有发现root tablet被分配,那么master就会将root tablet加入到unassigned tablets集合当中,确保root tablet会被分配。root tablet和metadata tablet通常存储在特殊的路径,以便启动的时候进行加载。
已经存在的tablet集合只有在tablet server新增/删除,两个tablet合并或者tablet拆分的时候才会发生变化,master会追踪这些变更但是除了tablet拆分。因为其他几个变更都是master发起的,但是tablet 拆分是tablet server发起的,所以做了特殊处理。tablet server会先将新的tablet信息记录到METADATA表中,记录完成之后再通知master。就算通知丢失了,那么在master让一个tablet server加载tablet的时候也会检测到这个拆分,然后由这个新的tablet server进行通知。
Note
因此tablet server读取到master让其加载的tablet时发现这个tablet只有master让其加载的部分信息,这就说明master没有感知到这个拆分,再次进行通知即可。
Tablet server
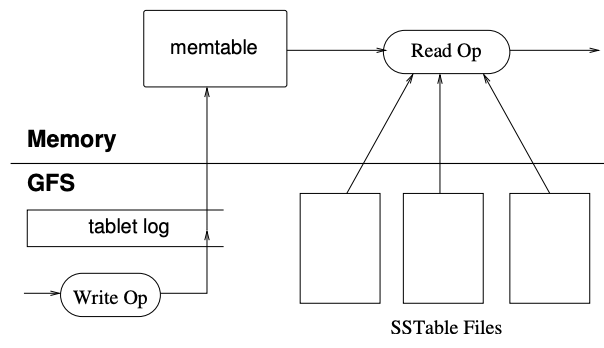 tablet数据持久化在GFS当中,已SSTable文件的格式存储。为了提高性能,使用内存缓存最近的数据,这是一个排序的缓冲区,叫做memtable,为了避免数据丢失采用了WAL的思想,会先将数据记录到tablet log当中,再修改到memtable。这样在恢复一个tablet数据的时候,只需要从METADATA当中获取到组成这个tablet的SSTable文件列表和可能包含tablet数据的指向commit log的redo指针即可。将SSTable文件的索引读取内存当中,并应用redo指针到memtable即成功还原了tablet的数据。
tablet数据持久化在GFS当中,已SSTable文件的格式存储。为了提高性能,使用内存缓存最近的数据,这是一个排序的缓冲区,叫做memtable,为了避免数据丢失采用了WAL的思想,会先将数据记录到tablet log当中,再修改到memtable。这样在恢复一个tablet数据的时候,只需要从METADATA当中获取到组成这个tablet的SSTable文件列表和可能包含tablet数据的指向commit log的redo指针即可。将SSTable文件的索引读取内存当中,并应用redo指针到memtable即成功还原了tablet的数据。
写操作的流程
- write操作到达tablet server
- tablet server检查请求格式是否正确,校验请求发送者是否有权限进行写操作。通过读取chubby文件中可写列表来判断是否有权限(一般总会命中chubby client cache)
- 写commit log。为了提升效率,通常是会按组批量提交的。
- commit log写入完成,插入到memtable当中。 读操作的流程
- 检查请求格式以及权限的是否正确
- 读操作查询的数据视图是SSTables和memtable合并的结果,由于都是按照字典序排列的,因此比较高效。 在split和merged操作期间仍然可以处理到来的读写操作。
BigTable查询结构图.excalidraw
⚠ Switch to EXCALIDRAW VIEW in the MORE OPTIONS menu of this document. ⚠ You can decompress Drawing data with the command palette: ‘Decompress current Excalidraw file’. For more info check in plugin settings under ‘Saving’
Excalidraw Data
Text Elements
client
chubby
tablet server3
root tablet location
(tableName, row key, column …)
tableName
memtable + sstable列表
tablet
metadata tablet location
1.根据表名找到这个表的metadata tablet
tablet server1
tablename → metadata tablet location
Root tablet
row key
tablet location
2.根据row key找到所属tablet分配的server
tablet server2
tabletN: [start row key, end row key] →. tablet location
metadata tablet
column family, column等信息
数据
3.根据row key, column key等查询指定的数据
Link to original
compactions
当memtable达到一定大小后,这个memtable就会变为不可变的,另外创建一个新的memtable用来继续处理写操作。这个不可变的memtable就会转换为SSTable并写入到GFS当中。
minor compaction处理有两个目的:
- 收缩tablet server使用的内存
- 减少tablet server宕机恢复时需要从commit log中读取的数据量。因为一旦写入gfs,那么这部分数据就不需要从commit log中恢复了。
每次minor compaction都会创建一个SSTable,如果不对其进行限制,那么读操作可能需要合并大量的SSTable。所以bigtable通过周期性地在后台执行merging compaction来限制SSTable的文件数量。
merging compaction读取部分SSTable文件和memtable,创建一个新的SSTable文件,然后就可以将旧的SSTable与memtable丢弃了。
将所有的SSTable文件重写为一个SSTable文件的merging compaction叫做major compaction。deletion entries在非major-compaction操作之后仍然存在,但是在major-compaction之后就不会存在了。BigTable通过major compaction回收删除数据使用的资源,确保这些数据及时从系统中消失,对于存储敏感数据的服务非常重要。
BigTable性能优化细节
这里介绍使得BigTable高性能的一些细节。
locality group
client可以将多个column family作为一个locality group。每个tablet中的locality group生成一个单独的SSTable。将通常不会一起访问的column family分离到单独的locality group可以提高读取效率。
可以说就是利用局部性原理,将会频繁一起访问的数据紧密存储。前面提到每个tablet都会有自己的memtable和sstable文件列表。现在看来,需要进一步划分一下,是tablet下的每个locality group有自己的memtable和sstable文件列表。
压缩
client可以控制locality group的sstable的压缩格式。当然,压缩的单位是sstable的block,这样的话读取的时候可以只解压block而不需要解压整个文件。虽然压缩率低了写,但是这样对读取少量数据是有利的。
用于提升读性能的cache
引入了两级cache。
- Scan Cache:缓存SSTable接口返回的kv对。
- Block Cache:缓存GFS读取的SSTable block。
Scan Cache对应用程序频繁读取相同数据的提升很大,Block Cache则通过局部性原理,对读取相邻数据场景的性能提升比较大。
bloom filter
读操作可能需要读取tablet中的所有sstables,这会涉及很多磁盘操作。client可以指定是否需要为locality group中的sstable列表创建布隆过滤器。可以用很少的一部分内存来减少大量的磁盘访问。
commit-log 实现
每个tablet都有一个commit-log的话。那么GFS会有大量的并发写文件,设计大量的磁盘寻道的耗时,并且影响组提交的优化。 因此改为了每个tablet server一个commit-log的实现方式。正常使用对性能提升很明显,但是对于recovery就变得比较复杂了。要是一个tablet server宕机了,然后它的tablet分配给了其他tablet server,比如有100个tablet server都收到了一个tablet,那么就需要读取这个commit log 100次来恢复这些tablet。 为了解决这个问题,在读取之前需要先对commit log中的entry按照(table, row name, log sequence number)进行排序,这个就可以通过一次磁盘寻道就够每个tablet获取自己的修改了。为了提升排序效率,还将文件划分为了64MB的段交给不同的tablet server进行并行排序,通过master进行协调。
加速tablet的recovery耗时
tablet recovery的耗时主要在commit log的应用上。当master将tablet从一个server移动到另一个server时
- 做一次minor compaction
- tablet server停止提供这个tablet
- 再做一次minor compaction。这个主要是为了消除12之间又有新的写入 这样移动之后,tablet不需要应用commit log,就可以快速恢复了。
利用不变性
因为SSTable文件的不可变性。对SSTable文件的访问不需要任何同步机制,唯一需要并发控制的地方就是memtable的并发写,于是又提供了memtable的写时复制来让读写可以并发。
基于不变性,tablet的split也变得很快,不需要为split出来的child tablets创建新的sstable集合,直接使用原来tablet的sstable列表即可。
总结
- 大型分布式系统非常脆弱
- 不要立即添加新功能,直到能够确定新功能如何被使用
- 监控很重要。系统的指标对定位和分析问题非常有帮助
- 设计简单非常重要