正常情况下,只要主库执行更新生成的所有 binlog,都可以传到备库并被正确地执行,备库就能达到跟主库一致的状态,这就是最终一致性。
但是mysql要保证高可用,只有最终一致性是不够的,因为在从库的数据延迟的情况下,是没有办法提供正确数据的。
主备延迟
主备切换可能是一个主动运维动作,比如软件升级、主库所在机器按计划下线等,也可能是被动操作,比如主库所在机器掉电。
与数据同步相关的时间点主要包括一下三个:
- 主库A执行完成一个事务,写入binlog,这个时刻记为T1.
- 传递给备库B,备库B接受完这个binlog的时刻记为T2.
- 备库B执行完成这个事务,这个时刻记为T3。 主备延迟就是同一个事务,在主库执行完成时间和在从库完成时间之间的差值,也就是T3-T1。
在备库上执行 show slave status 命令,它的返回结果里面会显示 seconds_behind_master,用于表示当前备库延迟了多少秒。计算方法是这样的:
- 每个事务的 binlog 里面都有一个时间字段,用于记录主库上写入的时间;
- 备库取出当前正在执行的事务的时间字段的值,计算它与当前系统时间的差值,得到 seconds_behind_master。
如果主备库机器的系统时间设置不一致,会不会导致主备延迟的值不准?
备库连接到主库的时候,会通过执行 SELECT UNIX_TIMESTAMP() 函数来获得当前主库的系统时间。如果这时候发现主库的系统时间与自己不一致,备库在执行 seconds_behind_master 计算的时候会自动扣掉这个差值。
网络正常情况下,主备延迟的主要来源是备库接收完 binlog 和执行完这个事务之间的时间差。
主备延迟的来源
- 从库所在机器性能比主库差。
- 备库压力大。一主多从,通过binlog输出到外部系统,如hadoop,让外部系统提供统计类查询能力。
- 大事务。要避免大事务的出现。
主备切换策略
由于主备延迟的存在,所以在主备切换的时候,有不同的策略。
可靠性优先策略
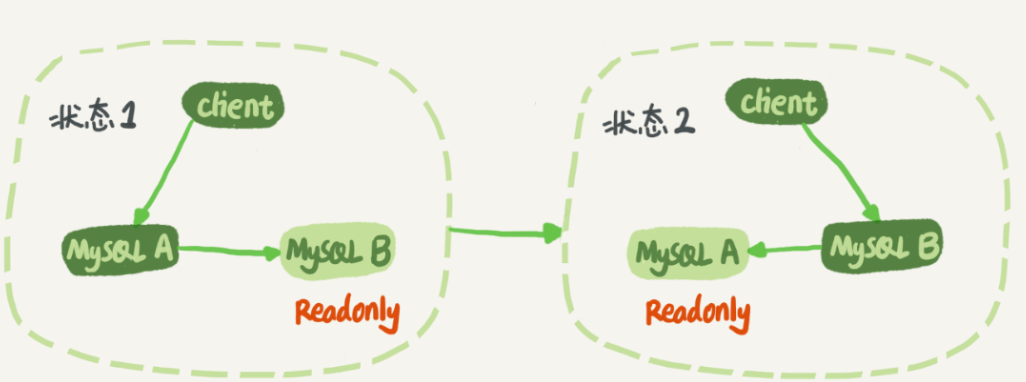 在上图的双M结构下,主从切换的详细过程是这样的:
在上图的双M结构下,主从切换的详细过程是这样的:
- 判断备库B现在的seconds_behind_master,如果小于某个值继续下一步,否则持续重试这一步。
- 把主库A改成只读状态,即把readonly设置为true。
- 判断备库B的seconds_behind_master的值,直到变为0为止。
- 把备库B改成可读写状态,也就是把readonly设置为false。
- 把业务请求切到备库B。 这个切换流程,一般是由专门的HA系统来完成的,注重可靠性,所以我们暂时称之为可靠性优先流程。
可以看到从第二步开始,直到第五步结束,这一段时间里系统是处理不可写状态的。所以需要第一步判断,让seconds_behind_master的值很小,让这个不可用状态的持续时间很短。
可用性优先策略
这个策略注重于可用性,也就是直接切换到备库B并且让B可以读写,那么系统就几乎没有不可用时间了。
但是如果备库B的数据要比A延迟的话,那么就有可能发生数据不一致性的问题。
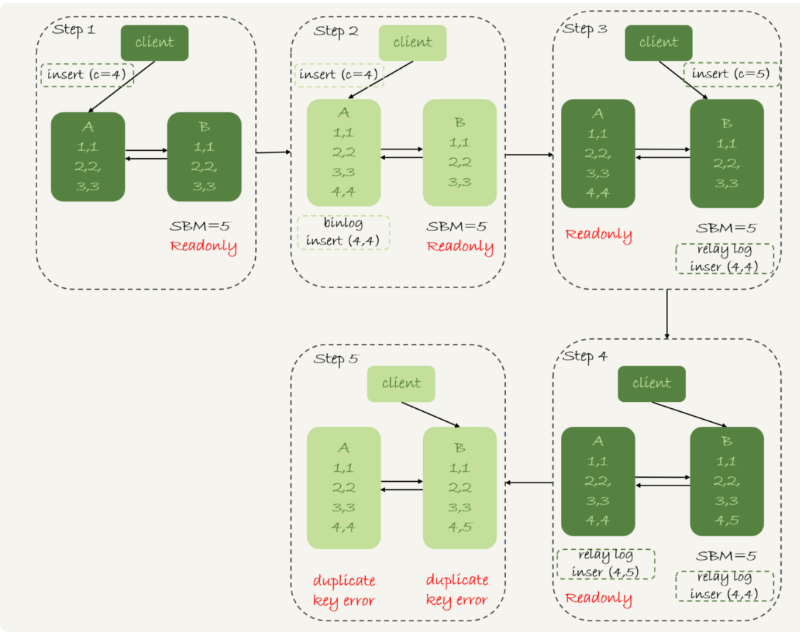
- 使用row格式的binlig时,数据不一致的问题更容易被发现。而使用mixed或者statement格式的binlog时,数据很可能悄悄地就不一致了。
- 主备切换的可用性优先策略会导致数据不一致。大多数情况下,都建议使用可靠性优先策略。
备库延迟几小时是为什么?
在前面介绍延迟的原因时,无论是偶发的查询压力,还是备份,备库的延迟一般是分钟级的,并且在备库恢复正常后都能够追上来。
但是,如果备库执行日志的速度持续低于主库生成日志的能力,那么这个延迟就可能成为小时级别,并且对于一个压力持续比较高的主库来说,备库可能永远都追不上主库。
于是就有了备库并行复制能力。
还是这张主备流程图,但是在并发的地方使用黑色箭头标粗了
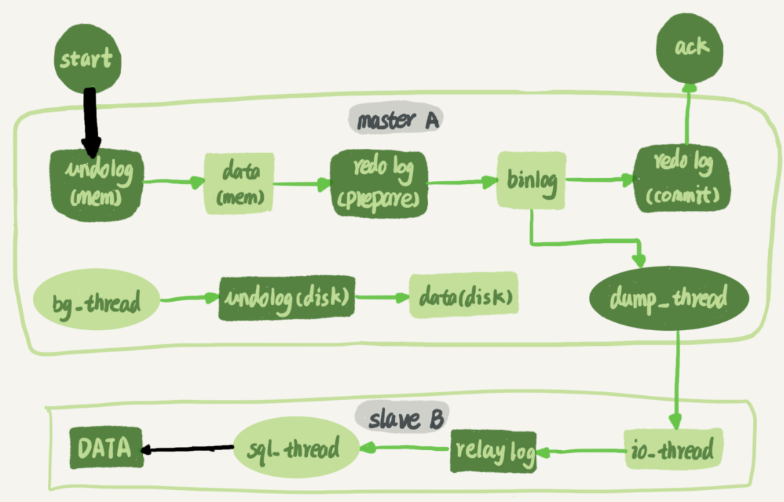 粗细代表并发度,可以看到第一个箭头要明显粗于第二个箭头。InnoDB引擎支持行锁,除了所有事务都更新同一行这种极端情况外,并发能力还是很不错的。
粗细代表并发度,可以看到第一个箭头要明显粗于第二个箭头。InnoDB引擎支持行锁,除了所有事务都更新同一行这种极端情况外,并发能力还是很不错的。
而备库上日志的执行,就是图中备库sql_thread更新数据的逻辑,而在mysql5.6版本之前,mysql只支持单线程复制,由此在主库并发高,TPS高时就会出现严重的主备延迟问题。
多线程复制,就是把图中只有一个的线程sql_thread变成多个线程,不过在具体的实现上有些区别:
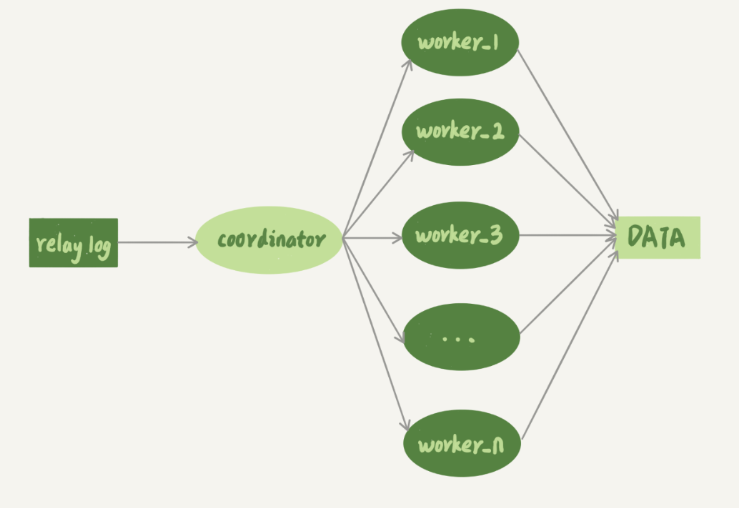
coordinator就是原来真正的sql_thread,不过现在它不再直接更新数据了,只负责读取中转日志和分发事务。真正更新日志的变成了worker线程。而work线程的个数,就是由参数slave_parallel_workers决定的。
coordinator在分发的时候,需要满足以下这两个基本要求:
- 不能造成更新覆盖。这就要求更新同一行的两个事务,必须被分发到同一个worker中
- 同一个事务不能被拆开,必须放到同一个worker中。
mysql5.7的并行复制策略
由参数slave-parrallel-type来控制并发复制策略:
- 配置为DATABASE,表示使用5.6版本的按库并行策略
- 配置为LIGICAL_CLOCK,使用类似于MariaDB的策略,事务组提交。不过5.7针对并行度做了优化。
所有commit状态的事务可以并行,但其实回顾一下两阶段提交的图
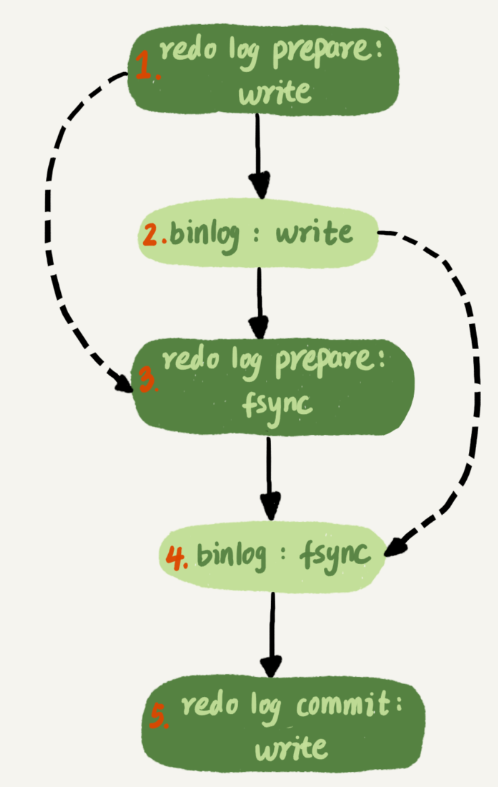 只要到达了redo log prepare阶段,就表示事务已经通过了锁冲突的检查,可以并行了。因此mysql5.7并行复制策略的思想是:
只要到达了redo log prepare阶段,就表示事务已经通过了锁冲突的检查,可以并行了。因此mysql5.7并行复制策略的思想是:
- 同时处于prepare状态的事务,在备库执行时时可以并行的。
- 处于prepare状态的事务,与处于commit状态的事务之间,在备库执行时也是可以并行的。
在数据可靠性的保证中介绍过两个参数bin_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count,用来延长binlog从write到fsync的时间,以此减少binlog的写盘次数。这样可以用来制造更多的“同时处于prepare阶段的事务”,增加备库复制的并行度。
mysql5.7.22的并行复制策略
在此版本中,mysql新增了一个并行复制策略,基于WRITESET的并行复制。
也相应新增了一个参数binlog-transaction-dependency-tracking,用来控制是否启用这个新策略。有三个可选值:
- COMMIT_ORDER,就是前面介绍的,根据同时进入prepare和commit来判断是否可以并行的策略。
- WRITESET,对于事务设涉及更新的每一行,计算出这一行的hash,组成集合writeset。如果两个事务的writeset没有交集,就可以并行。
- WRITESET_SESSION,在WRITESET的基础上多了一个约束,即在主库上同一个线程先后执行的两个事务,在备库执行的时候,要保证相同的先后顺序。