已经了解了mysql是依赖binlog来保证主从数据的一致的。那么现在正式学习这一部分。
mysql主备的基本原理
下图是主备切换的流程
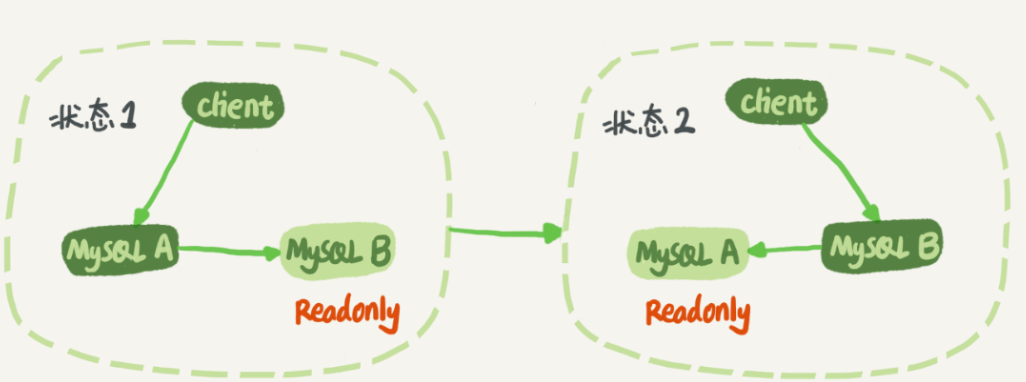
备库要设置成只读模式,主库用来进行读写,从库用来提供读并执行主库发送过来的binlog来保持同步。
而从库设置成只读,有以下目的:
- 防止误操作,有时一些运营类的查询语句会在备库上查询,设置成只读可以避免误操作。
- 防止切换逻辑有bug,比如切换过程出现双写,造成主备不一致。
- 用是否readonly判断主备。
备库只读了还怎么跟主库保持同步更新?
这是因为readonly设置对于超级权限用户是无效的,而同步线程就具有超级权限。
现在有一个A主B从的集群,那么在A上执行一个update语句,从节点A到节点B这条线的内部流程为:
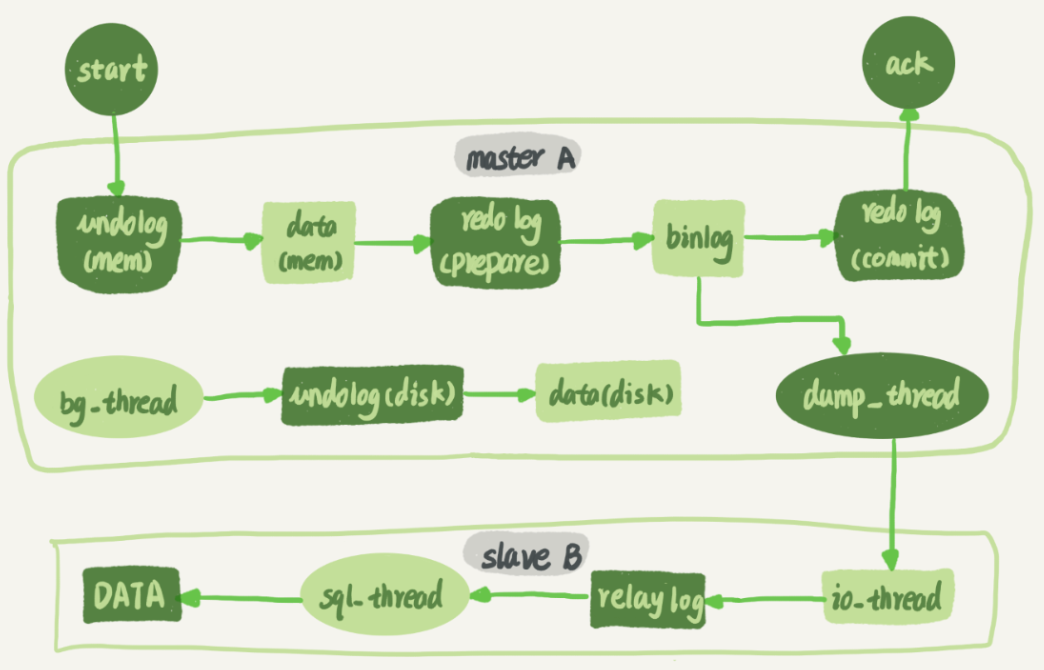 主库A与备库B之间维护了一个长连接,主库A内部有一个线程专门用于服务备库B的这个长连接。一个事务日志的同步过程如下:
主库A与备库B之间维护了一个长连接,主库A内部有一个线程专门用于服务备库B的这个长连接。一个事务日志的同步过程如下:
- 在备库B上通过change master命令,设置主库A的的ip,port,用户名,密码,以及从哪个位置开始请求binlog
- 在备库B上执行start slave命令,备库会启动两个线程,就是图中的io_thread和sql_thread。其中io_thread负责与主库建立连接。
- 主库A验证完用户名和密码之后,按照B传来的位置,从本地读取binlog,发送给B。
- 备库B拿到binlog之后,写到本地文件,称为中转日志(relay log)。
- sql_thread读取中转日志并解析出命令执行。
binlog三种格式
其实准确的说binlog只有两种格式,statement和row,第三种是这两种的混合格式mixed。
当格式为statement的时候,binlog记录的就是sql的原文语句。一句delete语句
mysql> delete from t /*comment*/ where a>=4 and t_modified<='2018-11-10' limit 1;记录的日志为:
 不过在这种格式下,delete语句并且带有limit是会发生警告的,因为这条语句在主备两个数据库执行的时候可能选择了不同的索引,limit使得选择不同索引的删除对象是不一样的,可能造成数据不一致,所以产生错误。
不过在这种格式下,delete语句并且带有limit是会发生警告的,因为这条语句在主备两个数据库执行的时候可能选择了不同的索引,limit使得选择不同索引的删除对象是不一样的,可能造成数据不一致,所以产生错误。
格式设置为row的话,中间的部分发生了改变,不再是sql语句了,而是两个event
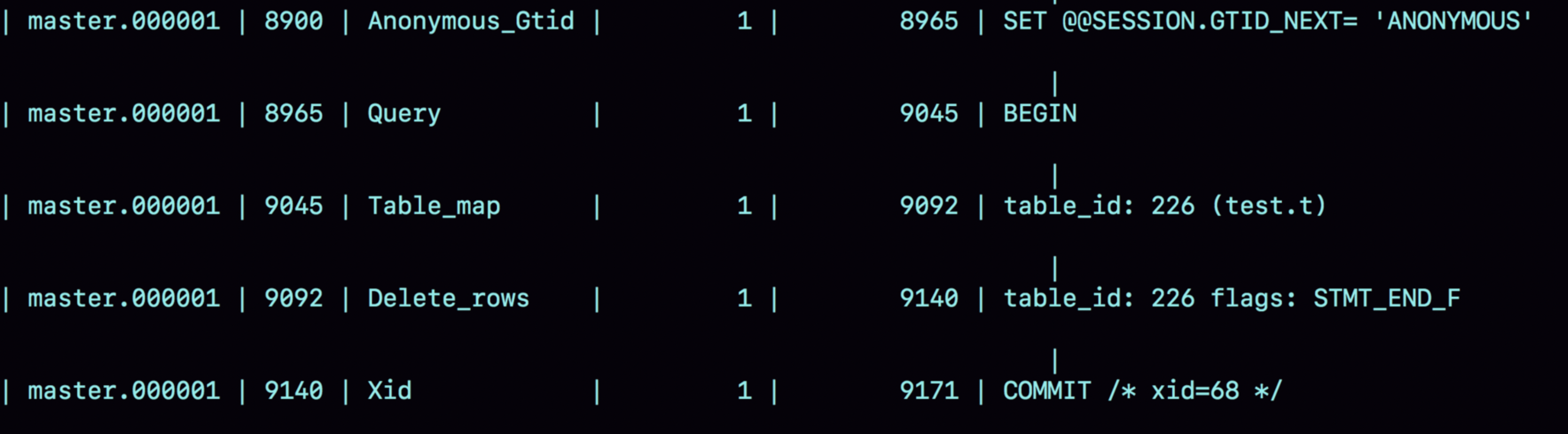
可以看到,==当 binlog_format 使用 row 格式的时候,binlog 里面记录了真实删除行的主键 id,这样 binlog 传到备库去的时候,就肯定会删除 id=4 的行,不会有主备删除不同行的问题==。
为什么会有mixed格式
一般这种结合两种方式的第三种方式就是为了结合两种方式的优点的。
- statement格式:节省空间,但是可能造成主备不一致。
- row格式:不会造成主备不一致,但是很占用空间。
mixed结合了两者的优缺点,取了折衷的方案:
- MySQL 自己会判断这条 SQL 语句是否可能引起主备不一致,如果有可能,就用 row 格式,否则就用 statement 格式。
不过现在越来越多的mysql要求使用row格式,虽然占用的空间多了,但是也同样记录了相当多的信息,无论是delelte、insert还是update,都记录了操作中涉及到的信息,借助这些信息当误操作的时候方便进行恢复。
循环复制问题
正常情况下主备的数据是保持一致的。并且生产环境下使用比较多的还是双M结构,也就是两个节点互为主备,但是同一时刻只有一个节点接受更新。
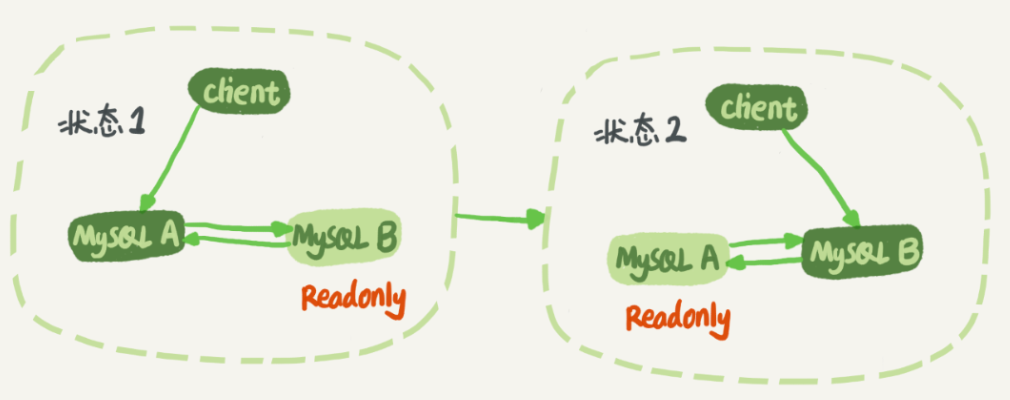
业务逻辑在节点 A 上更新了一条语句,然后再把生成的 binlog 发给节点 B,节点 B 执行完这条更新语句后也会生成 binlog。(我建议你把参数 log_slave_updates 设置为 on,表示备库执行 relay log 后生成 binlog)。
存在一个循环复制的问题,如果节点 A 同时是节点 B 的备库,相当于又把节点 B 新生成的 binlog 拿过来执行了一次,然后节点 A 和 B 间,会不断地循环执行这个更新语句,也就是循环复制了。
为了解决这个问题,MySQL 在 binlog 中记录了这个命令第一次执行时所在实例的 server id。按照如下逻辑解决循环复制的问题:
- 规定两个库的server id必须不同,否则不能设定为主备关系。
- 一个备库接到binlog并进行重放的过程中,会生成与原binlog的server id相同的新的binlog
- 每个库收到从主库发送过来的日志后,先判断server id,如果与自己的相同,那么就不执行。
这样就不会产生循环复制的问题了,当A产生的binlog都是A的server id,当A作为主库发送binlon给B时,B产生的binlog也是A的server id,然后B作为主库将binlog发送给A时,A就会判断与自己的server id相同将这些binlog抛弃。