根据锁的范围,mysql中的锁可以分为全局锁、表锁和行锁。
全局锁
全局锁就是对整个数据库实例加锁。通过命令flush tables with read lock(FTWRL)可以加上全局读锁,让整个数据库处于只读的状态,所有的更新语句、定义语句都会被阻塞。
全局锁的经典使用场景就是全库的逻辑备份,就是把整库每个表都select出来存成文本。
加锁让数据库变为只读,如果:
- 在主库上备份,那么备份期间都不能更新,业务基本停摆。
- 在从库上备份,备份期间不能执行主库同步过来的binlog,会造成主从延迟。
但是如果不加锁的话,备份系统备份得到的库不是一个逻辑时间点,这个视图是逻辑不一致的。
所以我们想要保证视图一致,那么提到这里,就可以回顾3.事务隔离中可重复读级别下的事务了,在可重复读隔离级别下启动事务就会获得一个一致性视图。并且由于MVCC的支持,这个过程中数据仍然是可以更新的。 官方自带的逻辑备份工具是 mysqldump。当 mysqldump 使用参数–single-transaction 的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。
不过一致性视图虽然好,但是只适用支持事务引擎的库,如果有表使用了不支持事务的引擎,那么就只能通过FTWRL的方法进行备份。
其实除了使用FTWRL让数据库变为只读状态外,还可以使用set global readonly=true让数据库进入只读状态,但这种方式是不推荐使用的。因为:
- 在一些系统中,readonly这个变量的值是会用来做其他逻辑,例如判断一个库是主库还是从库。而且修改global变量的影响太大。
- 在异常处理机制上有差异。执行FTWRL之后客户端发生异常,那么MYSQL会自动释放全局锁,整个库可以继续更新。而如果修改了readonly这个变量,客户端异常的话,数据库就会一致保持只读的状态,导致整个库不可更新,风险很大。
简单总结一下就是,对使用支持事务的引擎的库进行备份,可以利用可重复读隔离级别下事务的一致性视图来保证进行备份的时候仍然可以更新。对于不支持事务的引擎,就只能通过FTWRL加上全局锁变为只读状态来进行备份了。
表级锁
表级锁有两种:一个是表锁,另一种是元数据锁(MDL)。
表锁的语法是:locks tables ...read/write。与FTWRL类型,既可以使用unlock tables主动释放锁,也可以在客户端断开后自动释放锁。并且lock tables语法即限制了其他线程的读写,也限制了本线程接下来的操作对应。
例如locks tables t1 read, t2 write。那么接下来其他线程写t1,读写t2的语句都会被阻塞,而本线程也只能读t1,读写t2,不能写t1。其实这么看下来这里的read,write与读写锁类似,可以并发读,但是只能一个线程写。
另一个表级锁就是元数据锁了,这个锁不需要显式添加,在访问一个表的时候会被自动加上,这个是用来保证读写的正确性的,无论是对一个表进行读,还是对一个表进行写,如果这个时候表的结构发生了变化,导致读取的结果或者操作的字段跟表对不上肯定是不行的。
所以对一个表进行增删改查的时候都会自动加上MDL读锁,对表的结构进行变更的时候会加MDL写锁。这也是读写锁,可以并发读,但只能有一个写。
线上环境给表加字段问题
经常会遇到这样一个问题,在线上给一个小表添加一个字段,结果导致整个库都挂掉了。
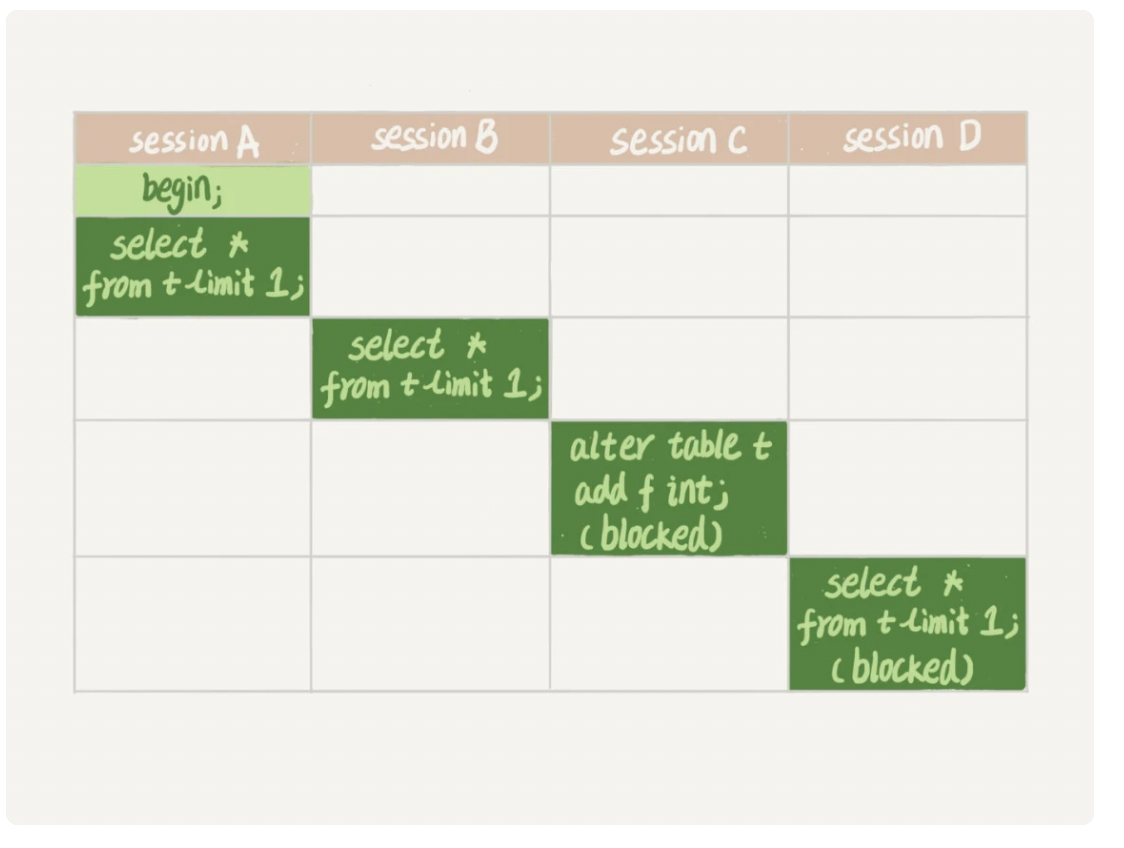
- sessionA先启动会获取MDL读锁,后面的SessionB需要的也是MDL读锁,所以可以正常执行。
- 但是SessionC需要获取MDL写锁,而此时SessionA和SessionB还没有结束释放读锁,所以SessionC会被阻塞。
- 注意,MDL写锁的优先级是要高于读锁的,SessionC阻塞在获取写锁的步骤中,后续的获取锁的Session也全部都会被阻塞。如果这个表上的查询语句频繁,并且客户端有重试机制(超时再起一个session),那么数据库的线程就很快爆满。
在线上加字段的时候需要注意长事务,因为只要事务不提交,那么MDL锁就一直不会释放。所以如果执行DDL的时候如果有长事务正在执行,可以考虑先暂停DDL,或者kill这个长事务。在mysql的information_schema库的innodb_trx表中,可以看到当前正在执行的事务。
但是如果变更的表是一个热点表,请求非常频繁,那么kill事务就没有什么作用了。比较理想的机制是,在alter table中设置一个过期时间,如果过期时间内能够拿到MDL写锁最好,拿不到也不要阻塞后面的语句。之后再通过重试命令重复这个过程。
Mariadb合并了AliSQL的这个功能,支持如下的语句:
ALTER TABLE tbl_name NOWAIT add column ...
ALTER TABLE tbl_name WAIT N add column ... 行锁
mysql的行锁是在引擎层由引擎自己实现的,如innodb,也有不支持行锁的引擎,如myisam。不支持行锁的话就意味着并发控制只能使用表锁,这样同一时刻一张表上只能有一个更新在执行,这对业务的并发度影响很大。
行锁就是针对数据库中行记录的锁,事务A更新了一行,事务B也要更新这一行就必须等待A更新完成。
数据库中存在一些不是那么一目了然的设计,为了避免程序出现非预期的情况,一定要理清这些概念。 首先就是两阶段锁。
两阶段锁
两阶段锁协议
在innodb事务中,行锁是在需要的时候才加上的,但是不会在使用结束就立即释放,而是在事务结束之后才使用的。
所以在事务当中要锁住多个行,那么要尽量把最可能造成锁冲突、最可能影响并发度的锁放在最靠后的位置。
有这样的场景。顾客要在影院购买电影票,现在将整个事务简化为:
- 从顾客的账户余额中扣除电影票的票价
- 给影院的账户余额增加电影票的票价
- 记录一条日志
把最可能影响并发度的锁放在最后,那么可以确定,就是按照1,3,2的顺序执行事务。
但是这个影院如果做一天的活动,低价预售一年内的所有票,活动一开始mysql就立即挂掉了,登陆服务器,cpu占用100%,但是每秒就执行不到100的事务。这种场景的出现就与接下来要讲的死锁和死锁检测有关了。
死锁与死锁检测
当不同线程出现资源循环以来,互相等待对方释放资源的时候就出现了死锁。而出现死锁后有两种处理的策略:
- 等待超时。达到超时时间后线程退出,这个超时时间可以通过参数innodb_lock_wait_timeout来设置,innodb的默认值是50,也就是出现死锁后,要等待50s后第一个被锁住的线程才会退出,其他线程才能够执行。这个时间对于线上服务来说是不可能忍受的。但是又不能设置一个很短的值,否则会误伤很多正常的事务。所以一般采用第二个策略。
- 主动死锁检测。这是参数innodb_deadlock_detect控制的,innodb的默认值就是on。当一个事务被锁的时候,就会进行死锁检测,也就是查询它锁以来的线程有没有被别人锁住,如果发现循环依赖就主动回滚死锁链条当中的一个事务。
前面提到的场景中,很明显没有死锁的情况,造成故障的原因在于死锁检测。所有的事务都要更新影院的账户余额这一行,每个新来的被堵住的线程都要判断是否因为自己的加入发生了死锁,对于这个线程来说,这是一个时间复杂度为O(n)的操作,但是对于n个线程整体来说,这就是O(n^2)的操作。
对于这样热点行的更新,如果同时有1000个线程要更新这个行,那么死锁检测就是100万这个量级的,虽然最后的结果是没有死锁,但是这个过程当中已经浪费了大量的cpu资源。
热点行的更新问题
最简单粗暴的方法就是如果能够确定一定不会出现死锁,那么可以临时将死锁检测关掉。但是这样是存在风险的,可能会出现大量超时,对业务有损。
另一个思路就是控制并发度。如果一个线程最多只有10个线程同时更新,那么死锁检测的成本就很低,不会出现这个问题。并发度的控制有三个思路:
- 直接在客户端限制,但是这个方法不太可行,因为客户端数量多了之后,就算每个客户端只有很少的线程数,整体数量也很多。
- 在中间件限制。
- 修改mysql源码,让对于相同行的更新在进入引擎前排队,这样innodb引擎内容就不会有大量的死锁检测工作了。