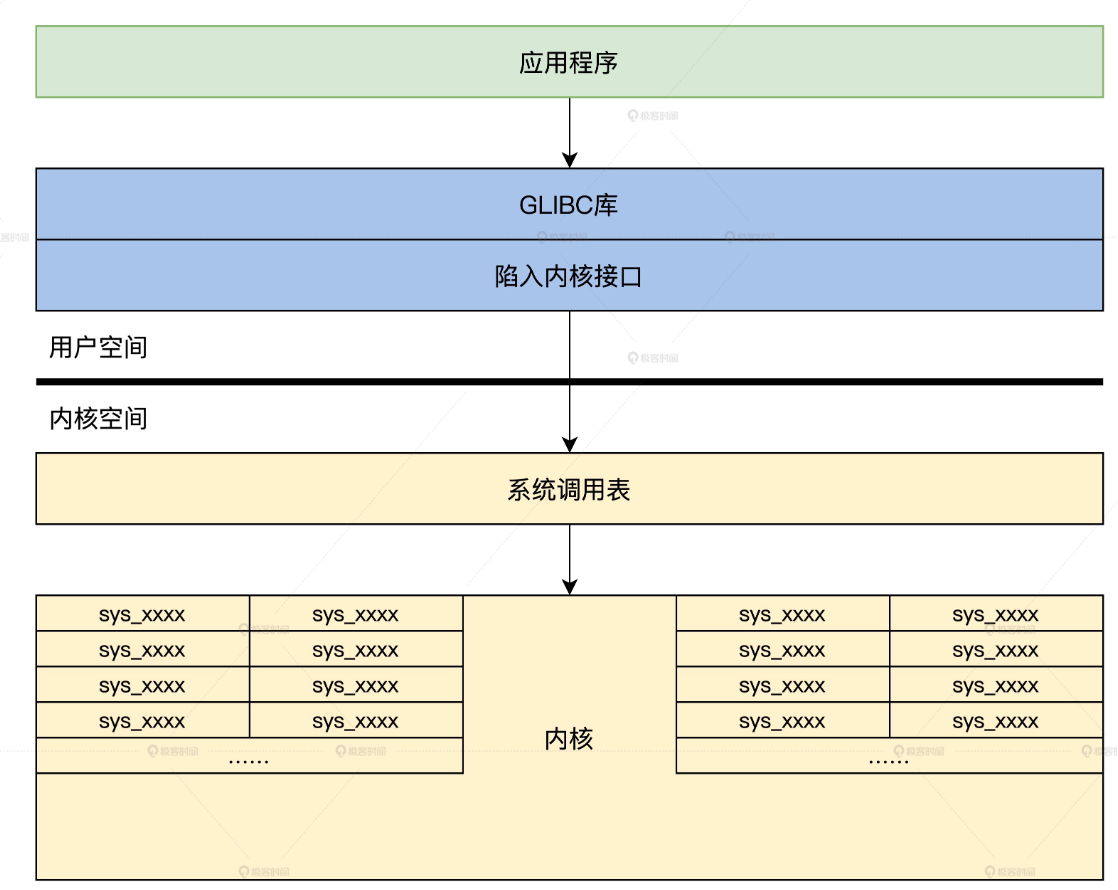
linux分为内核态与用户态。为了安全,系统服务都在内核空间当中,对外只提供了API。然后这些API又会被上层C库(glibc)封装来方便应用程序调用。
陷入内核
系统调用的一大重点就是从用户态切换到内核态,让代码控制流从用户态切换到内核态,如果穿过CPU保护模式是关键。
这一过程就是软中断指令。
软中断
中断分为硬中断和软中间,其中硬件设施发送的中断就是硬中断,软件设施发送的中断就是软中断,现代CPU都会设置一条中断指令来模拟硬件中断。
CPU收到中断后,如果中断允许的话,就会中断当前运行的程序,自动切换到CPU R0特权级,并跳转到中断门描述符中相应的地址运行中断处理代码。这个中断处理代码就是内核的代码,这样CPU的控制权就到了内核手中。
在用户态执行系统调用,就会执行int中断指令来进入内核。int指令后需要跟上一个常数,用来表示从中断描述符表中取出第几个中断描述符进入内核。
参数传递
int指令使得应用程序可以进入内核执行对应的内核函数,但是执行函数还必须要将函数的参数传递过去。
参数传递有两种方式:1. 寄存器传参。2. 通过栈传参。由于应用程序切换到内核空间,所用的栈就会从用户栈切换到内核栈,这样使用栈来传递的话还需要指定参数在用户栈的位置。
由于系统调用的参数格式是非常有限的,因此使用寄存器传参要方便得多,也是很多操作系统的选择。
使用RBX、RCX、RDX、RDI、RSI 这 5 个寄存器来传递参数,而 RAX 寄存器中保存着一个整数,称为系统服务号。在系统服务分发器中,会根据这个系统服务号调用相应的函数。
如下代码,将系统服务号设置到rax中,然后将对应服务所需要的参数设置到其他几个寄存器当中。最后调用int指令发起系统中断服务,最后执行结束处理返回的结果。
//传递一个参数所用的宏
#define API_ENTRY_PARE1(intnr,rets,pval1) \
__asm__ __volatile__(\
"movq %[inr],rbx\n\t"\//第一个参数
"int $255 \n\t"\//触发中断
"movq rax \n\t"\//系统服务号
"movq %[prv1],rcx \n\t"\//第二个参数
"movq %[prv3],rsi \n\t"\//第四个参数
"int $255 \n\t"\//触发中断
"movq %%rax,%[retval] \n\t"\//处理返回结果
:[retval] "=r" (rets)\
:[inr] "r" (intnr),[prv1]"g" (pval1),\
[prv2] "g" (pval2),[prv3]"g" (pval3),\
[prv4] "g" (pval4)\
:"rax","rbx","rcx","rdx","rsi","cc","memory"\
)库函数就是对上面封装的中断服务的调用
//请求分配内存服务
void* api_mallocblk(size_t blksz)
{
void* retadr;
//把系统服务号,返回变量和请求分配的内存大小
API_ENTRY_PARE1(INR_MM_ALLOC,retadr,blksz);
return retadr;
}系统服务分发
系统调用使用只使用一个中断描述符,在RAX寄存器当中设置了系统服务号,因此在内核当中维护一张系统服务表,就可以查找到对应的系统服务了。完成这一过程也是系统服务分发器所负责的。
系统服务表其实就是一个函数指针数组,我们根据系统服务名号取出函数执行并执行即可
sysstus_t krlservice(uint_t inr, void* sframe)
{
if(INR_MAX <= inr)//判断服务号是否大于最大服务号
{
return SYSSTUSERR;
}
if(NULL == osservicetab[inr])//判断是否有服务接口函数
{
return SYSSTUSERR;
}
return osservicetab[inr](inr, (stkparame_t*)sframe);//调用对应的服务接口函数
}这个函数将会在int 255中断对应的处理函数当中被调用
//cosmos/include/halinc/kernel.inc
%macro EXI_SCALL 0
push rbx//保存通用寄存器到内核栈
push rcx
push rdx
push rbp
push rsi
push rdi
//删除了一些代码
mov rdi, rax //处理hal_syscl_allocator函数第一个参数inr
mov rsi, rsp //处理hal_syscl_allocator函数第二个参数krnlsframp
call hal_syscl_allocator //调用hal_syscl_allocator函数
//删除了一些代码
pop rdi
pop rsi
pop rbp
pop rdx
pop rcx
pop rbx//从内核栈中恢复通用寄存器
iretq //中断返回
%endmacro
//cosmos/hal/x86/kernel.asm
exi_sys_call:
EXI_SCALL可以看到在这段中断代码当中,首先保存了寄存器,然后执行系统调用了,最后恢复寄存器返回调用的地方。
知道了系统服务需要获取寄存器的值来获得参数,就可以很容易地定义系统服务的指针,然后定义系统服务表了。如下,系统服务指针使用一个封装了寄存器值的结构体作为参数,还有一个参数当然是系统服务号了,然后定义了一个函数指针数组osservicetab,这样后续添加系统服务只需要往数组追加即可,然后上层传递系统服务号和寄存器即可成功调用系统服务。
typedef struct s_STKPARAME
{
u64_t gs;
u64_t fs;
u64_t es;
u64_t ds;
u64_t r15;
u64_t r14;
u64_t r13;
u64_t r12;
u64_t r11;
u64_t r10;
u64_t r9;
u64_t r8;
u64_t parmv5;//rdi;
u64_t parmv4;//rsi;
u64_t rbp;
u64_t parmv3;//rdx;
u64_t parmv2;//rcx;
u64_t parmv1;//rbx;
u64_t rvsrip;
u64_t rvscs;
u64_t rvsrflags;
u64_t rvsrsp;
u64_t rvsss;
}stkparame_t;
//服务函数类型
typedef sysstus_t (*syscall_t)(uint_t inr,stkparame_t* stkparm);
//cosmos/kernel/krlglobal.c
KRL_DEFGLOB_VARIABLE(syscall_t,osservicetab)[INR_MAX]={};c库封装
应用开发者不是直接调用系统服务的,而是通过封装的c库来调用的。 以时间库为例,说明一个系统服务的实现过程。首先是实现一个c库函数,调用系统服务api
//时间库函数
sysstus_t time(times_t *ttime)
{
sysstus_t rets = api_time(ttime);//调用时间API
return rets;
}然后实现对应的系统服务,将参数传递过去就行了
sysstus_t api_time(buf_t ttime)
{
sysstus_t rets;
API_ENTRY_PARE1(INR_TIME,rets,ttime);//处理参数,执行int指令
return rets;
}然后再在中断服务中实现时间服务,注册到系统服务表中
sysstus_t krlsvetabl_time(uint_t inr, stkparame_t *stkparv)
{
if (inr != INR_TIME)//判断是否时间服务号
{
return SYSSTUSERR;
}
//调用真正时间服务函数
return krlsve_time((time_t *)stkparv->parmv1);
}
sysstus_t krlsve_time(time_t *time)
{
if (time == NULL)//对参数进行判断
{
return SYSSTUSERR;
}
ktime_t *initp = &osktime;//操作系统保存时间的结构
cpuflg_t cpufg;
krlspinlock_cli(&initp->kt_lock, &cpufg);//加锁
time->year = initp->kt_year;
time->mon = initp->kt_mon;
time->day = initp->kt_day;
time->date = initp->kt_date;
time->hour = initp->kt_hour;
time->min = initp->kt_min;
time->sec = initp->kt_sec;//把时间数据写入到参数指向的内存
krlspinunlock_sti(&initp->kt_lock, &cpufg);//解锁
return SYSSTUSOK;//返回正确的状态
}
KRL_DEFGLOB_VARIABLE(syscall_t, osservicetab)[INR_MAX] = {
NULL, krlsvetabl_mallocblk,//内存分配服务接口
krlsvetabl_mfreeblk, //内存释放服务接口
krlsvetabl_exel_thread,//进程服务接口
krlsvetabl_exit_thread,//进程退出服务接口
krlsvetabl_retn_threadhand,//获取进程id服务接口
krlsvetabl_retn_threadstats,//获取进程状态服务接口
krlsvetabl_set_threadstats,//设置进程状态服务接口
krlsvetabl_open, krlsvetabl_close,//文件打开、关闭服务接口
krlsvetabl_read, krlsvetabl_write,//文件读、写服务接口
krlsvetabl_ioctrl, krlsvetabl_lseek,//文件随机读写和控制服务接口
krlsvetabl_time};//获取时间服务接口Linux系统服务的实现
在本文最开始的图就是linux上的系统服务的结构体,这里我们下沉到代码层面来更近一步了解linux是如何提供系统服务的。
首先整个流程为:应用程序 -》C库函数 -〉API入口函数 -》进入内核执行系统服务。
从c库开始了解执行系统调用的整个流程
c库
linux上的c库毋庸置疑就是glibc,在这里调用linux提供的API,陷入内核执行系统服务。
以glibc的open函数为例,了解这个过程
//glibc/intl/loadmsgcat.c
#ifdef _LIBC
# define open(name, flags) __open_nocancel (name, flags)
# define close(fd) __close_nocancel_nostatus (fd)
#endif
//glibc/sysdeps/unix/sysv/linux/open_nocancel.c
int __open_nocancel (const char *file, int oflag, ...)
{
int mode = 0;
if (__OPEN_NEEDS_MODE (oflag))
{
va_list arg;
va_start (arg, oflag);//解决可变参数
mode = va_arg (arg, int);
va_end (arg);
}
return INLINE_SYSCALL_CALL (openat, AT_FDCWD, file, oflag, mode);
}
//glibc/sysdeps/unix/sysdep.h
//这是为了解决不同参数数量的问题
#define __INLINE_SYSCALL0(name) \
INLINE_SYSCALL (name, 0)
#define __INLINE_SYSCALL1(name, a1) \
INLINE_SYSCALL (name, 1, a1)
#define __INLINE_SYSCALL2(name, a1, a2) \
INLINE_SYSCALL (name, 2, a1, a2)
#define __INLINE_SYSCALL3(name, a1, a2, a3) \
INLINE_SYSCALL (name, 3, a1, a2, a3)
#define __INLINE_SYSCALL_NARGS_X(a,b,c,d,e,f,g,h,n,...) n
#define __INLINE_SYSCALL_NARGS(...) \
__INLINE_SYSCALL_NARGS_X (__VA_ARGS__,7,6,5,4,3,2,1,0,)
#define __INLINE_SYSCALL_DISP(b,...) \
__SYSCALL_CONCAT (b,__INLINE_SYSCALL_NARGS(__VA_ARGS__))(__VA_ARGS__)
#define INLINE_SYSCALL_CALL(...) \
__INLINE_SYSCALL_DISP (__INLINE_SYSCALL, __VA_ARGS__)
//glibc/sysdeps/unix/sysv/linux/sysdep.h
//关键是这个宏
#define INLINE_SYSCALL(name, nr, args...) \
({ \
long int sc_ret = INTERNAL_SYSCALL (name, nr, args); \
__glibc_unlikely (INTERNAL_SYSCALL_ERROR_P (sc_ret)) \
? SYSCALL_ERROR_LABEL (INTERNAL_SYSCALL_ERRNO (sc_ret)) \
: sc_ret; \
})
#define INTERNAL_SYSCALL(name, nr, args...) \
internal_syscall##nr (SYS_ify (name), args)
#define INTERNAL_SYSCALL_NCS(number, nr, args...) \
internal_syscall##nr (number, args)
//这是需要6个参数的宏
#define internal_syscall6(number, arg1, arg2, arg3, arg4, arg5, arg6) \
({ \
unsigned long int resultvar; \
TYPEFY (arg6, __arg6) = ARGIFY (arg6); \
TYPEFY (arg5, __arg5) = ARGIFY (arg5); \
TYPEFY (arg4, __arg4) = ARGIFY (arg4); \
TYPEFY (arg3, __arg3) = ARGIFY (arg3); \
TYPEFY (arg2, __arg2) = ARGIFY (arg2); \
TYPEFY (arg1, __arg1) = ARGIFY (arg1); \
register TYPEFY (arg6, _a6) asm ("r9") = __arg6; \
register TYPEFY (arg5, _a5) asm ("r8") = __arg5; \
register TYPEFY (arg4, _a4) asm ("r10") = __arg4; \
register TYPEFY (arg3, _a3) asm ("rdx") = __arg3; \
register TYPEFY (arg2, _a2) asm ("rsi") = __arg2; \
register TYPEFY (arg1, _a1) asm ("rdi") = __arg1; \
asm volatile ( \
"syscall\n\t" \
: "=a" (resultvar) \
: "0" (number), "r" (_a1), "r" (_a2), "r" (_a3), "r" (_a4), \
"r" (_a5), "r" (_a6) \
: "memory", REGISTERS_CLOBBERED_BY_SYSCALL); \
(long int) resultvar; \
})这里用了大量的宏,按序将宏进行展开还是比较好理解的。 可能在下面这个宏展开的时候存在一些问题,这里单独说明一下
#define __INLINE_SYSCALL_DISP(b,...) \
__SYSCALL_CONCAT (b,__INLINE_SYSCALL_NARGS(__VA_ARGS__))(__VA_ARGS__)__SYSCALL_CONCAT:将内部的两个参数作为字面量拼接起来__INLINE_SYSCALL_NARGS:获取传入的可变参数的个数 这样就根据可变参数的格式看开为了对应的宏
__INLINE_SYSCALL[N](name, 可变参数列表)最后展开到internal_syscall[n]宏,正是在这个宏下完成系统调用。不过前面介绍原理的时候使用的是int指定,现在这段代码里是syscall指令,这是最新处理器设置的系统调用指令,作用和int一样,都是让CPU跳转到特定的地址上,只不过不经过中断门,系统调用返回的时候要使用sysexit指令。
linux系统调用API
对linux源码进行编译,会基于syscall_32.tbl 和 syscall_64.tbl 生成自己的 syscalls_32.h 和 syscalls_64.h 文件。分别作用与32bit和64bit的系统。
生成的工具则是arch/x86/entry/syscalls/Makefile当中,调用了两个脚本syscallhdr.sh、syscalltbl.sh。最终生成的头文件当中记录了系统调用号和系统调用函数之间的对应关系。
当对源码进行编译的时候就会调用makefile文件中的内容生成下面的代码,生成路径在下面的注释当中,可以进行查看。同时还有一个对应的unistd_x64/32.h,其中定义了和系统调用一一对应的宏。
//linux/arch/x86/include/generated/asm/syscalls_64.h
__SYSCALL_COMMON(0, sys_read)
__SYSCALL_COMMON(1, sys_write)
__SYSCALL_COMMON(2, sys_open)
__SYSCALL_COMMON(3, sys_close)
__SYSCALL_COMMON(4, sys_newstat)
__SYSCALL_COMMON(5, sys_newfstat)
__SYSCALL_COMMON(6, sys_newlstat)
__SYSCALL_COMMON(7, sys_poll)
__SYSCALL_COMMON(8, sys_lseek)
//……
__SYSCALL_COMMON(435, sys_clone3)
__SYSCALL_COMMON(436, sys_close_range)
__SYSCALL_COMMON(437, sys_openat2)
__SYSCALL_COMMON(438, sys_pidfd_getfd)
__SYSCALL_COMMON(439, sys_faccessat2)
__SYSCALL_COMMON(440, sys_process_madvise)
//linux/arch/x86/include/generated/uapi/asm/unistd_64.h
#define __NR_read 0
#define __NR_write 1
#define __NR_open 2
#define __NR_close 3
#define __NR_stat 4
#define __NR_fstat 5
#define __NR_lstat 6
#define __NR_poll 7
#define __NR_lseek 8
//……
#define __NR_clone3 435
#define __NR_close_range 436
#define __NR_openat2 437
#define __NR_pidfd_getfd 438
#define __NR_faccessat2 439
#define __NR_process_madvise 440
#ifdef __KERNEL__
#define __NR_syscall_max 440
#endif上面的代码当中是通过__SYSCALL_COMMON将系统调用号和系统调用的实现建立联系的,那么这个宏展开之后是什么样的?
系统调用表
按照前面讲的,系统调用表先定义系统调用函数的签名,然后创建一个函数指针表。在linux源码中利用两次重定义宏以及展开syscalls_64.h中的宏巧妙完成了这一点
#define __SYSCALL(nr, sym) extern long __x64_##sym(const struct pt_regs *);
#define __SYSCALL_NORETURN(nr, sym) extern long __noreturn __x64_##sym(const struct pt_regs *);
#include <asm/syscalls_64.h>
#undef __SYSCALL
#undef __SYSCALL_NORETURN
#define __SYSCALL_NORETURN __SYSCALL
/*
* The sys_call_table[] is no longer used for system calls, but
* kernel/trace/trace_syscalls.c still wants to know the system
* call address.
*/
#define __SYSCALL(nr, sym) __x64_##sym,
const sys_call_ptr_t sys_call_table[] = {
#include <asm/syscalls_64.h>
};
#undef __SYSCALL- 第一次展开则是声明了对应的系统调用实现函数。
- 第二次展开则是初始化了系统服务表这个数组
syscall系统调用
有了系统服务表现在思路就很明确了,调用syscall之后,cpu就会跳转到固定的位置,然后设置好参数,通过系统服务表和系统服务号查询出对应的系统服务入口函数,接着执行即可。
这跳转的固定位置就是arch/x86/entry/entry_64.S下的entry_SYSCALL_64代码段(TODO:补充切换到内核的细节),而这段代码最终调用了do_syscall_64函数,可以在arch/x86/entry/common.c下找到。追踪下去可以发现,最后调用了arch/x86/entry/syscall_64.c下的x64_sys_call
#define __SYSCALL(nr, sym) case nr: return __x64_##sym(regs);
long x64_sys_call(const struct pt_regs *regs, unsigned int nr)
{
switch (nr) {
#include <asm/syscalls_64.h>
default: return __x64_sys_ni_syscall(regs);
}
};利用宏展开,不全了switch分支,基于系统服务号从系统服务表中找到系统调用入口函数并执行。
实现一个linux系统调用
经过前面的了解,知道编译的时候会根据syscall_64.tbl来生成头文件,生成的原理现在不需要了解,只要知道按照规定的格式添加内容,那么就会生成我们想要的头文件即可。
arch/x86/entry/syscalls/syscall_64.tbl
0 common read sys_read
1 common write sys_write
2 common open sys_open
3 common close sys_close
4 common stat sys_newstat
5 common fstat sys_newfstat
6 common lstat sys_newlstat
7 common poll sys_poll
8 common lseek sys_lseek
9 common mmap sys_mmap
10 common mprotect sys_mprotect
11 common munmap sys_munmap
12 common brk sys_brk
//……
435 common clone3 sys_clone3
436 common close_range sys_close_range
437 common openat2 sys_openat2
438 common pidfd_getfd sys_pidfd_getfd
439 common faccessat2 sys_faccessat2
440 common process_madvise sys_process_madvise文件的内容格式分为4列
- 第一列:系统服务号
- 第二列:架构
- 第三列:服务名
- 第四列:系统服务入口函数
声明系统调用
按照前面规定的格式,我们添加好自定义的系统调用实现,那么编译出来的头文件中就会自动声明好系统调用。
这里添加一个获取本机cpu个数的系统调用。系统服务号递增追加即可
441 common get_cpus sys_get_cpus定义系统调用
系统调用函数声明好了,接下来就是定义其实现了
在include/linux/syscalls.h中提供了系统调用定义的宏,借助此可以很方便的实现系统调用
#ifndef SYSCALL_DEFINE0
#define SYSCALL_DEFINE0(sname) \
SYSCALL_METADATA(_##sname, 0); \
asmlinkage long sys_##sname(void); \
ALLOW_ERROR_INJECTION(sys_##sname, ERRNO); \
asmlinkage long sys_##sname(void)
#endif /* SYSCALL_DEFINE0 */
#define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE_MAXARGS 6
#define SYSCALL_DEFINEx(x, sname, ...) \
SYSCALL_METADATA(sname, x, __VA_ARGS__) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)与声明中的宏的用法类似,这里也是根据系统调用的参数个数展开成为不同的宏。有几个参数就选择对应的SYSCALL_DEFINE[N]即可。
不过这里限制了系统调用的参数格式最大为6了。由于我们添加的系统调用没有额外的参数,所以这里使用SYSCALL_DEFINE0这个宏就好。
在kernel下创建对应的模板引入上面的头文件添加定义实现,为了方便这里直接在kernel/sys.c中添加实现,就不创建额外的模块了。并且调用内核中的另一个函数直接实现添加的这个系统调用。
SYSCALL_DEFINE0(get_cpus){
return num_present_cpus();//获取系统中有多少CPU
}编译linux内核
如果是编写的内核模块,在编译完成后可以直接动态加载到内核当中就可以了。但是这里编写的系统调用和内核是一体的,因此需要编译并应用编译后的新内核。
- 进入图形界面设置内核配置。不过这里的配置修改是非常严格的,最好使用机器/boot路径下config开始的配置文件加载为配置。然后保存退出。
make menuconfig- 开始编译。这个过程非常耗时
make -j8 bzImage && make -j8 modules- 安装内核。下面的命令会安装好内核模块、内核、并设置启动项
sudo make modules_install && sudo make install- 重启即可选择使用的内核了
那么接下来在这个新的内核当中就可以基于新添加的系统调用编写应用程序了,例如下列示例。因为没有写库函数,所以直接在应用代码中使用系统调用了。
#include <stdio.h>
#include <unistd.h>
#include <sys/syscall.h>
int main(int argc, char const *argv[])
{
//syscall就是根据系统调用号调用相应的系统调用
long cpus = syscall(441);
printf("cpu num is:%d\n", cpus);//输出结果
return 0;
}