除了k8s网络模型与CNI网络插件中讲述的模式外,还有一种纯三层的网络方案。典型例子就是flannel的host-gw模式和Calico项目。
host-gw模式
这个工作原理比较简单。
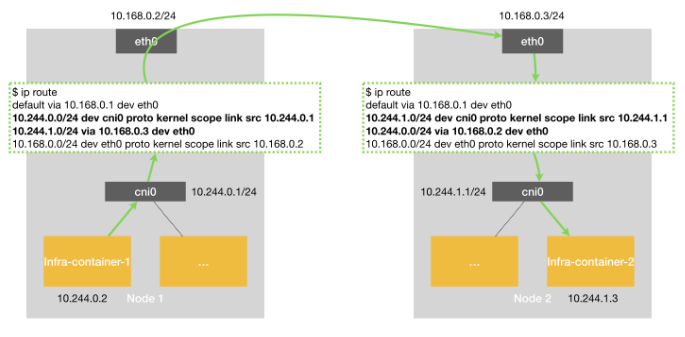
host-gw 模式的工作原理,其实就是将每个 Flannel 子网(Flannel Subnet,比如:10.244.1.0/24)的“下一跳”,设置成了该子网对应的宿主机的 IP 地址。所以在Node1上可以看到如下的路由规则:
$ ip route
...
10.244.1.0/24 via 10.168.0.3 dev eth0可以看到Node2中容器所在的网段全部通过eth0设备发送到下一跳, 10.168.0.3,即是Node2的地址。
容器发出的数据包通过cni0到达宿主机后,就匹配到了路由表中的这条规则。这里是将宿主机的eth0作为了网关,将IP包从一个网络发送到另一个网络。这也正是host-gw名称的由来。
Flannel 子网和主机的信息,都是保存在 Etcd 当中的。flanneld 只需要 WACTH 这些数据的变化,然后实时更新路由表即可。据实际的测试,host-gw 的性能损失大约在 10% 左右,而其他所有基于 VXLAN“隧道”机制的网络方案,性能损失都在 20%~30% 左右。
由于host-gw利用下一跳来设置目的MAC地址,然后经过二层网络到达目的宿主机。所以Flannel host-gw 模式必须要求集群宿主机之间是二层连通的。需要注意的是,宿主机之间二层不连通的情况也是广泛存在的。比如,宿主机分布在了不同的子网(VLAN)里。但是,在一个 Kubernetes 集群里,宿主机之间必须可以通过 IP 地址进行通信,也就是说至少是三层可达的。
三层网络方案里的龙头老大就是Calico项目。
Calico
Calico提供的解决方式与Flannel的host-gw一样,也是在每台宿主机上添加一个如下的路由规则:
<目的容器IP地址段> via <网关的IP地址> dev eth0其中网关的IP地址,正是容器所在宿主机的IP地址。但是不同于flannel通过Etcd和宿主机上的flannel来维护路由信息的做法,Cailco使用了一个“重型武器”来自动在整个集群中分发路由信息。
这个重型武器就是BGP。Border Gateway Protocol,即边界网关协议。
BGP是Linux原生支持的, 专门在大规模数据中心中维护不同的“自治系统”之间路由信息的、无中心的路由协议。 而所谓的一个自治系统,指的是一个组织管辖下的所有 IP 网络和路由器的全体。你可以把它想象成一个小公司里的所有主机和路由器。在正常情况下,自治系统之间不会有任何“来往”。
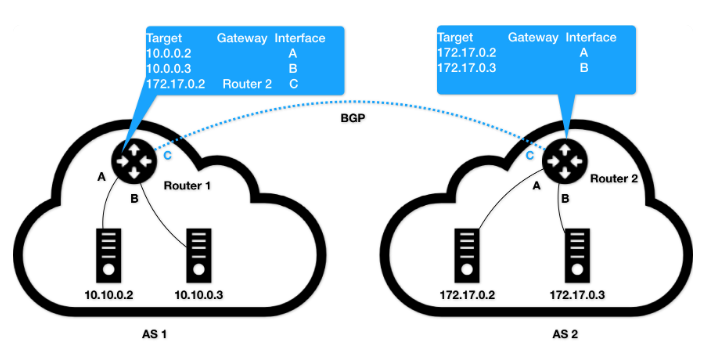 这两个自治系统里的主机要想通过IP地址直接通信,就需要使用路由器将这两个自治系统连接起来。而负责将自治系统连接起来的路由器就是边界网关。与普通路由器的不同就在于它拥有其它自治系统的主机路由信息。
这两个自治系统里的主机要想通过IP地址直接通信,就需要使用路由器将这两个自治系统连接起来。而负责将自治系统连接起来的路由器就是边界网关。与普通路由器的不同就在于它拥有其它自治系统的主机路由信息。
对于复杂的网络结构,如果还需要依靠人工来对边界网关的路由表进行配置和维护,那是不现实的。而这便是BGP所要完成的。在使用了 BGP 之后,你可以认为,在每个边界网关上都会运行着一个小程序,它们会将各自的路由表信息,通过 TCP 传输给其他的边界网关。而其他边界网关上的这个小程序,则会对收到的这些数据进行分析,然后将需要的信息添加到自己的路由表里。
所以BGP就是大规模网络中实现节点路由信息共享的一种协议。Calico项目的结构由三部分组成:
- Calico的CNI插件。这是Calico与k8s进行对接的部分。
- Felix。这是一个DaemonSet,负责在宿主机上插入路由规则,以及维护Calico所需的网络设备等工作。
- BIRD。这是一个BGP的客户端,负责在集群里分发路由规则等信息。
除了对路由信息的维护方式之外,Calico 项目与 Flannel 的 host-gw 模式的另一个不同之处,就是它不会在宿主机上创建任何网桥设备。
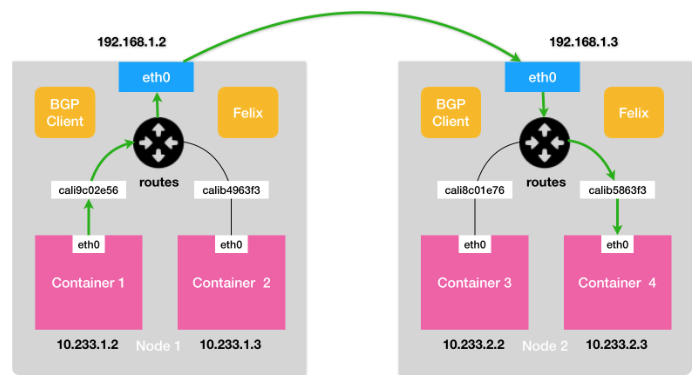 Calico的CNI插件会为每个容器创建一个veth pair,然后将一端放置在宿主机上。由于没有使用CNI的网桥模式,Calico的CNI插件还要为每个容器的veth pair设备配置一条路由规则,用于接收传入的IP包。比如Node2的container4容器:
Calico的CNI插件会为每个容器创建一个veth pair,然后将一端放置在宿主机上。由于没有使用CNI的网桥模式,Calico的CNI插件还要为每个容器的veth pair设备配置一条路由规则,用于接收传入的IP包。比如Node2的container4容器:
10.233.2.3 dev cali5863f3 scope link这样,容器发出的IP包出现在宿主机上,宿主机就能够根据路由表的下一跳的IP地址,转发给正确的网关。剩余的内容与host-gw一样了。
而这里核心的下一跳路由规则就是由Calico的Felix进程维护的,而路由规则信息是BIRD通过BGP协议传输而来的。
BGP的消息内容可以简单理解为下面:
[BGP消息]
我是宿主机192.168.1.3
10.233.2.0/24网段的容器都在我这里
这些容器的下一跳地址是我Calico将集群里的所有节点都当作是边界路由器来处理,这些节点称为BGP Peer。
要注意,Calico维护的网络在默认配置下,是Node-To-Node Mesh的模式,每台宿主机上的BGP Client都要与其它的节点的BGP Client进行通信来交换数据,这个连接的数量是以的规模增长的,所以只在节点的数量N小的时候使用。 更大规模的集群中,需要使用Route Reflector模式,Calico专门指定一个或者几个节点来专门跟所有的BGP建立连接从而学到所有的路由规则,其它节点只用跟这几个专门的节点交换信息就可以获取整个集群的路由规则了。
IPIP模式
Flannel host-gw 模式最主要的限制,就是要求集群宿主机之间是二层连通的。而这个限制对于 Calico 来说,也同样存在。 对于两台处于不同子网的宿主机,假如我们有两台处于不同子网的宿主机 Node 1 和 Node 2,对应的 IP 地址分别是 192.168.1.2 和 192.168.2.2。Node1上的容器要发送到Node2上,按照前面所讲Node1上由如下路由规则:
10.233.2.0/16 via 192.168.2.2 eth0可以这个下一跳却并不在这个子网当中,所以这个IP包无法发送到Node2。 解决的方法就是打开Calico的IPIP模式。
这个模式下的容器通信原理如下:
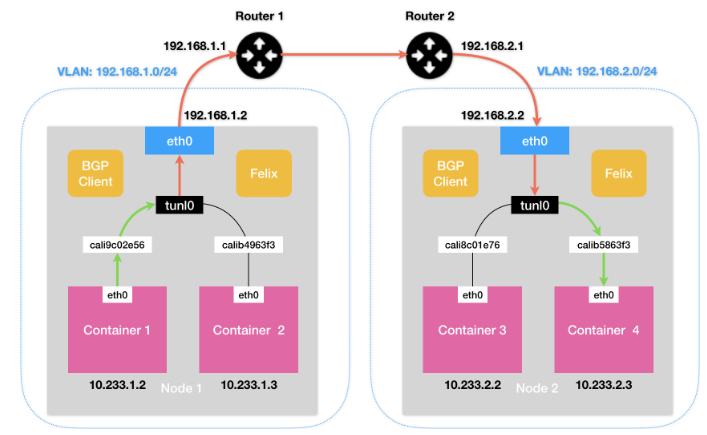 在这个模式下Felix添加的路由规则是有所不同的:
在这个模式下Felix添加的路由规则是有所不同的:
10.233.2.0/24 via 192.168.2.2 tunl0下一跳地址不变,但是负责发送IP包的设备不是宿主机的eth0,而是tunl0了。这个tunl0设备是一个IP 隧道(IP tunnel)设备。
发送到IP隧道的IP包,会被Linux内核的IPIP驱动接管,IPIP驱动将这个IP包直接封装在一个宿主机网络IP包当中。
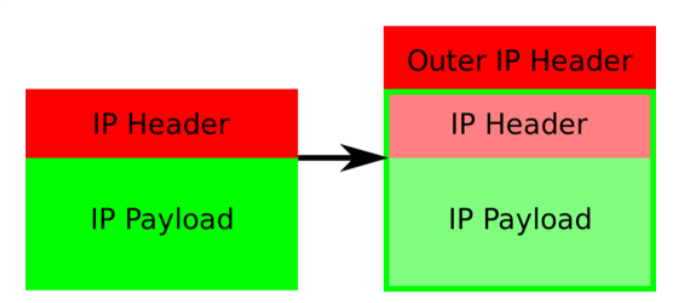 而这个IP包的目的地址就是原始IP包的下一跳地址。原始IP包被封装为新IP包的Payload。而Node1和Node2是能够IP联通的。到达Node2后再进行拆包,最终拿到原始的IP包,经过路由规则和veth pair设备到达目的容器的内部。
而这个IP包的目的地址就是原始IP包的下一跳地址。原始IP包被封装为新IP包的Payload。而Node1和Node2是能够IP联通的。到达Node2后再进行拆包,最终拿到原始的IP包,经过路由规则和veth pair设备到达目的容器的内部。
IPIP模式通过封装,将IP包的网关转发变成了两台主机的网络通信,又有些类似隧道技术。目前遇到的种种问题和种种解决方案无一不是在说明计算机领域的任何问题都能够通过加上一层中间层来解决。
当 Calico 使用 IPIP 模式的时候,集群的网络性能会因为额外的封包和解包工作而下降。在实际测试中,Calico IPIP 模式与 Flannel VXLAN 模式的性能大致相当。所以,在实际使用时,如非硬性需求,我建议你将所有宿主机节点放在一个子网里,避免使用 IPIP。
在私有云环境下,通过将宿主机之间的网关也加入到BGP Mesh之中就可以避免使用IPIP。而Calico提供了两种将宿主机网关设置成BGP Peer的解决方案。
- 所有宿主机都跟宿主机网关建立BGP Peer关系。
- 与前面将BGP的Route Reflector模式类似,使用一个或多个独立组件负责搜集整个集群里的所有路由信息,这里直接由 Route Reflector 兼任即可。它们负责监听Etcd中宿主机和对应网段的变化,然后把这些消息通过BGP发送给网关即可。