datafusion的定位是一个in-memory的查询引擎。其设计目标为:
- 开箱即用:基本无需配置就能提供一个快速、世界级的查询引擎
- 一切可定制:一切行为都可自定义
- 无架构:并不是datafusion没有架构,而是没有提出新的架构。使用行业最佳实践,而不是尝试使用前沿的未经验证的技术 可以看出,将datafusion作为学习查询引擎是不错的,可以迅速跟进行业最佳实践完善基础。
扩展
- TableProvider:用来对接datasource
- Catalog与CatalogProvider:定义自己的catalog,schema和table list
- LogicalPlanBuilder:构建LogicalPlan,用于自己用来对接自己的查询语句
- ScalarUDF,AggregateUDF,WindowUDF:对接用户自定义函数
- AnalyzerRule, OptimizerRule,PhysicalOptimizerRule:添加自定义的计划重写通道
- QueryPlanner:扩展QueryPlaner来支持自定义的logical或physical node
Query Plan与Execution
一个查询引擎的核心点在于执行计划的构建与执行。datafusion中按照行业的最佳实践构建执行计划的过程如下
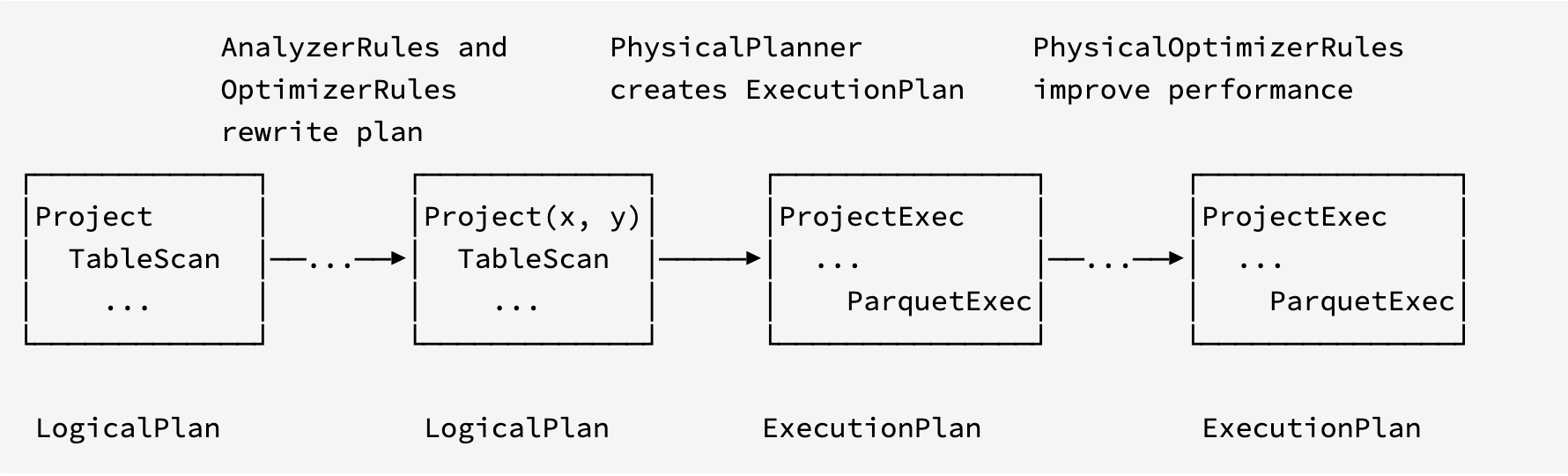
- 逻辑计划——LogicalPlan
- 执行计划——ExecutionPlan 以及在这个过程当中对Plan进行转化的各种Rules。
为了便于操作,在LogicalPlan之前对外提供了sql和DataFrame两种接口,换言之只要对接了LogicalPlan,用户可以添加任何自己期望的上层接口。
logical plan
逻辑计划由LogicalPlan节点和Schema感知的Expr表达式组成,是和物理执行独立的语句。一个LogicalPlan是由LogicalPlan组成的有向无环图,Expr可能嵌入在每一个LogicalPlan节点当中。 LogicalPlan可以被TreeNode api重写;Expr也可以被TreeNode api同样,还可以被ExprSimplier简化。
Physical Plan
物理计划ExecutionPlan也是由ExecutionPlan节点组成的有向无环图,可能嵌入的表达式也是由Expr变为了PhysicalExpr trait的实现。
与逻辑计划相比,物理计划有着更加具体的执行计算的信息以及计算过程中的数据流。
Execution
得到了ExecutionPlan之后就开始执行计算了。
执行过程中会产生一个数据流,不断地从这个流程读取数据。
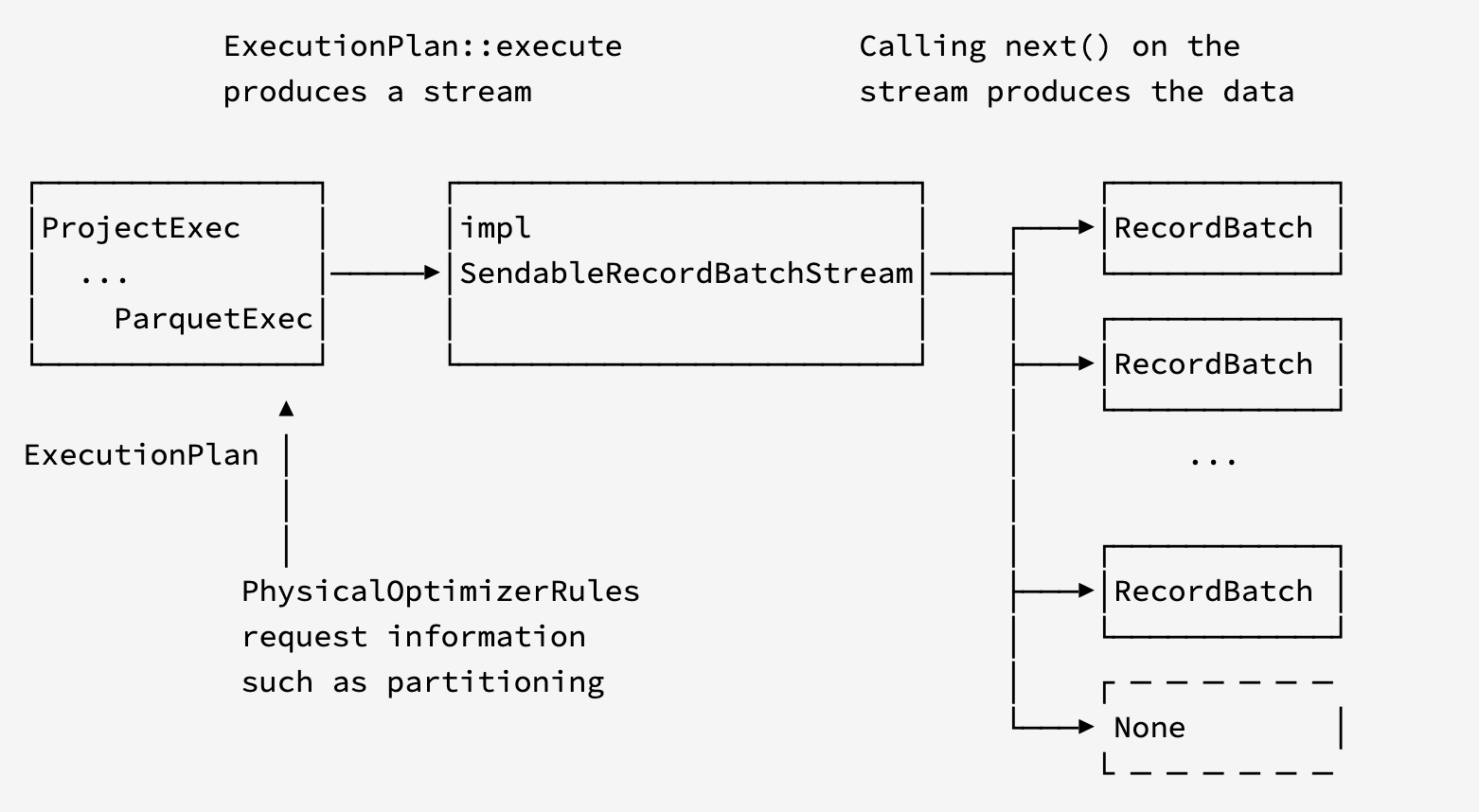
线程调度
datafusion使用target_partitions线程来从 SendableRecordBatchStream中逐步计算出结果。通过使用tokio运行时的task任务来实现并发,任务的高效性由tokio运行时保证。
状态管理与配置
ConfigOptions中包含控制datafusion执行的配置。除了配置还有如下几个状态
- SessionContext:创建LogicalPlan所需的表定义、注册的函数等信息的状态
- TaskContext:执行过程中MemoryPool,DiskManager,ObjectStoreRegistry状态在这里
- ExecutionProps:记录执行的一些属性,例如开始时间
资源管理
在执行计划的可以通过MemoryPool和DiskManager控制内存和临时本地磁盘空间的使用量。其他运行时选项可以在RuntimeEnv上找到。
工程目录的组织方式
- datafusion_common:公共trait和类型
- datafusion_execution:执行所需的结构体
- datafusion_expr:LogicalPlan,Expr和其它逻辑计划相关的结构
- datafusion_functions:标量函数所在的包
- datafusion_functions_nested:
ARRAYs,MAPs andSTRUCT类型的标量函数所在包 - datafusion_optimizer:优化器
- datafusion_physical_plan:ExecutionPlan和相关的表达式
- datafusion_physical_expr:PhysicalExpr和相关表达式
- datafusion_sql:对外提供的sql接口
论文
datafusion有相关的论文详细描述了其架构,datafusion论文。
架构
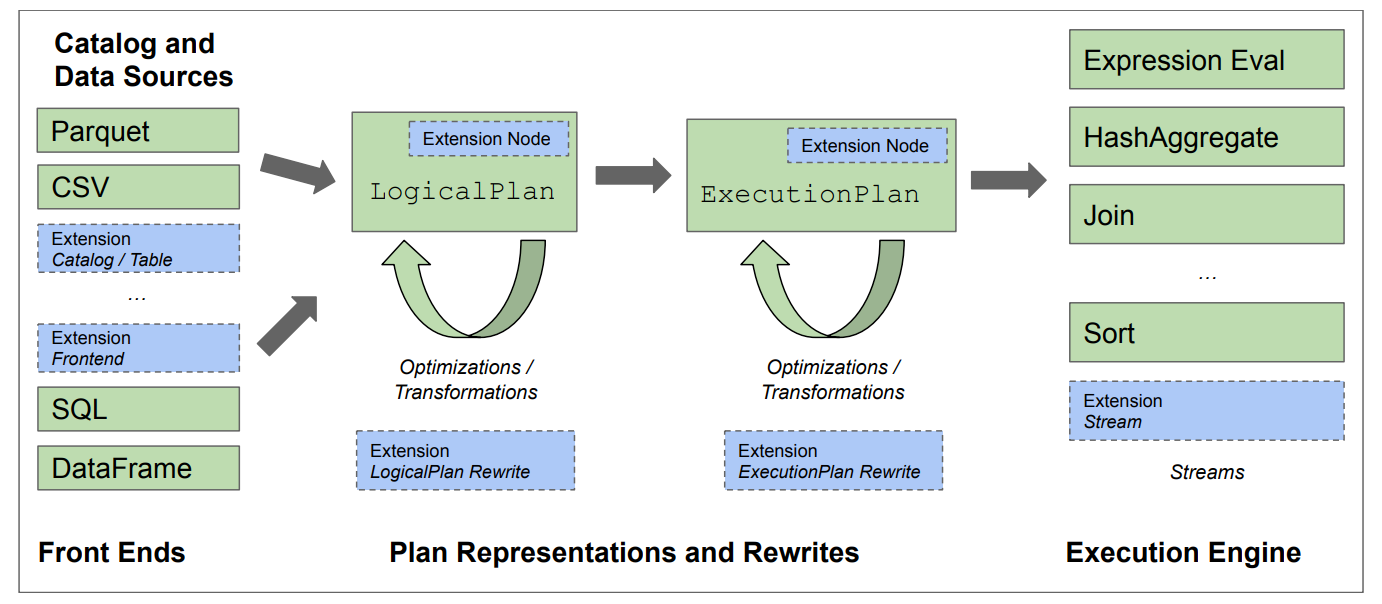
- catalog和datasource:提供了schema和数据布局与位置信息
- front end:用于提供创建LogicalPlan树的对外接口
- optimizers:重写LogicalPlan为最优的形式
- LogicalPlan转为更下一层的ExecutionPlan,包含中间结果的特征
- 还有重写ExecutionPlan的优化器
- 以及最后用于执行ExecutionPlan的stream