介绍
Raft是一种管理复制日志的一致性算法。与其它 分布式算法 ,例如Paxos相比,Raft算法更容易理解,并且能够更加容易的应用到实际的系统中,而Paxos自身的数据结构还需要大量的修改才能够应用到实际的系统中。
Raft将算法分解成了三个模块:领导者选举、日志复制、安全。并且通过强一致性减少状态机的状态,这样就减少了需要考虑的状态的数量。
Raft算法无论是可理解性,还是实现难度都要优于其它算法,通常作为分布式一致性算法的首选。具有一些独特的特性:
- 强领导人:Raft使用一种更强的领导能力形式。比如,日志条目只从领导人发送给其它服务器。简化了对复制日志的管理。
- 领导选举:Raft算法使用一个随机计时器来选举领导人。基于任何一致性算法都必须实现的心跳机制。
- 成员关系调整:Raft使用一种共同一致的方法来处理集群变更的问题,在这种方法下,处于调整过程中的两种不同的配置集群中大多数机器会有重叠,使得集群在变更成员的时候依旧可以工作。
复制状态机
一致性算法维护的就是一组服务器的状态机的一致性,这样这一组服务器都能够提供正确的服务,并且在一些机器宕机的情况下仍能工作。
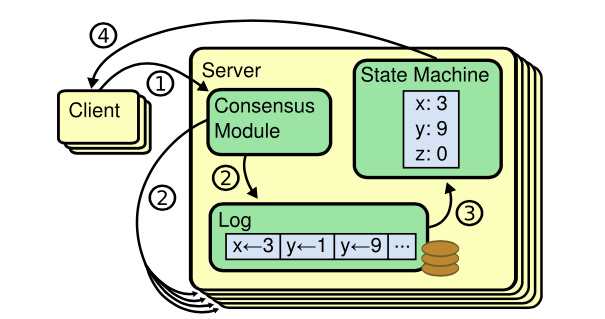
一致性算法管理着来自客户端指令的复制日志。状态机从日志中处理相同顺序的相同指令,所以产生的结果也相同。
如上图所示,复制状态机是基于复制日志实现的,每个服务器都存储着指令的日志,并按照日志的顺序执行,相同的日志按照相同的顺序执行,那么所有的状态机就能够从一个相同的状态变为另一个一致的状态。服务器集群形成了一个高可靠的状态机。
在实际系统中使用的一致性算法通常由以下特点:
- 安全性保证。在非拜占庭错误情况下,包括网络延迟、分区、丢包、重复和乱序等错误都可以保证正确。
- 可用性。只要集群中大多数机器可用,就可以保证可用。一个包含5个节点的集群可以容忍两个节点的失败。
- 不依赖时序保证一致性。物理时钟错误或者极端的消息延迟只有在最坏情况下才会导致可用性问题
- 一条指令只要在一轮远程调用中由大半节点响应就可以完成,少部分较慢的节点不会影响。
Raft一致性算法
Raft通过选举出一个领导者,然后赋予它全部的管理复制日志的职责来保证一致性。领导者从客户端接收日志条目(log entries),然后将日志复制到其它服务器上,并告诉其它服务器什么时候可以安全地将日志应用到它们的状态机中。
通过领导人的方式,将一致性问题分为了三个子问题:
- 领导选举。当现存领导人发生故障的时候,需要选举出一个新的领导人。
- 日志复制。领导人必须从客户端接收日志条目(log entries),并强制要求其它节点和自己保持一致。
- 安全性。如果一个服务器确定应用了一条日志条目,那么其他服务器就不能在相同的日志索引位置处应用不同的执行。
Raft基础
Raft中的每个服务器节点都处于三种状态之一:
- 跟随者
- 候选人
- 领导者
通常情况下,系统中有且只有一个领导人,其余都是跟随者。跟随者不会主动发起请求,只会响应。候选人是选举领导人的一个中间状态,领导人从候选人中产生。
转换关系如下:
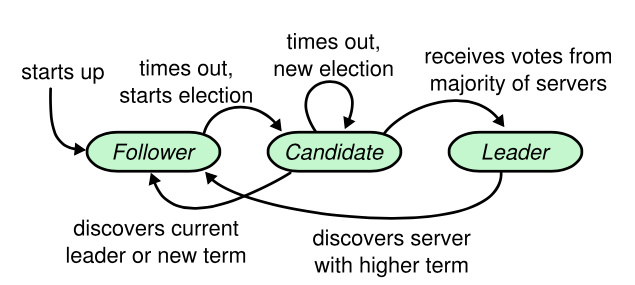
跟随者只响应来自其它服务器的请求,如果跟随者收不到请求,那么它就会变成候选人并发起一次选举,获得大多数选票的候选人将成为领导人。
Raft将时间分为任意长度的任期。任期用连续的整数标记,每一段任期从一次选举开始。一个或者多个候选人参与选举,如果一个候选人赢得选举,接下来它就在任期内承担领导人的职责。但是一个任期可以因为瓜分选票而选举失败,开始下一轮新的选举。
每个节点都记录着当前任期,这一编号单调递增。服务器通信的时候都会交换当前任期号,据此来判断自己的状态过期还是对方的状态过期。
如果一个节点收到了一个过期的任期号的请求,那么它会直接拒绝这个请求。如果一个节点收到的请求的任期号比自己的大,那么它会更新自己的任期号到较大的编号值,并且这个节点如果是候选人或者领导人的话,如上图所示,会立即变为跟随者状态。
Raft算法中节点之间通过RPC通信,并且只需要两种类型的RPC。用来选举领导人的请求投票(RequestVote)rpc;用来复制日志的附加条目(AppendEntries)RPC,同时这一RPC也被用来当作心跳机制。
后面为了传输快照增加了第三种RPC。
领导人选举
所有节点启动的时候都是跟随者状态。通过心跳机制来触发选举,如果在超时之前从领导人接收到有效的RPC,那么就会保持跟随者身份,否则就会变成候选人并发起选举。
一次选举过程中,跟随者先增加自己的任期编号,然后变成候选人状态,再并行地向集群中其它节点发起请求投票RPC来给自己投票,结果由三种:
- 成为赢得选举成为领导人。
- 其它服务器成为领导人。
- 在选举超时时间内没有选举出领导人,开始下一轮选举。
每个服务器最多为一个任期投一次票。
- 当一个候选人获得了集群大多数服务器节点针对同一个任期号的投票,那么他就成为领导人。大多数选票保证了只有一个候选人会赢得选举。成为领导人之后就会向其它节点发送心跳消息来避免有人发起新的选举。
- 在候选人等待投票期间,可能会收到来自一个领导人的附加条目RPC,如果领导人的任期不小于候选人的当前任期,那么候选人会承认这个领导人并变回跟随者。否则会拒绝这个rpc并保持候选人状态。
- 同时出现多个候选人,导致选票瓜分,而无法产生领导人。这样的话,每个候选人都会超时,然后发起新的选举。为了避免选票瓜分,每个服务器的超时时间都是随机产生的,如果出现了瓜分选票的情况,==每个候选人的选举时间也是随机的==,避免同时发起新的选举。
日志复制
集群选举出领导人之后就可以为客户端提供服务了。客户端的每个请求都包含一条被复制状态机执行的指令,领导人将这条指令存入条目附加到日志中去,然后并行发起附加条目RPC给其它服务器,让他们复制这条日志,复制之后,才会将日志应用到状态机,然后将执行结果返回给客户端。
领导人决定何时将日志条目安全应用到状态机中:这种日志条目叫做已提交。
领导人从客户端接收到一条日志条目之后,并没有立即提交,而是通过发起并行的AppendEntries RPC请求来将日志条目复制到其它服务器节点上,其它服务器复制成功之后会响应,领导人得到过半的响应之后可以将这个日志条目提交了,然后就可以响应客户端执行结果了。在后续作为心跳的的AppendEntries RPC请求中包含已提交日志的索引值,其它服务器据此进行提交。
Raft的日志匹配特性(Log matching Property) 有以下特性:
- 不同日志中的两条日志具有相同的任期号和索引,那么这两条日志相同。这是因为一个领导人最多在一个任期里在一个指定的日志索引位置创建一条日志条目。
- 两条相同日志之前的日志也是相同的。在附加日志RPC中,领导人会携带新日志条目前紧挨着的索引和任期号,如果在跟随者中找不到对应的日志,那么跟随者就拒收新的日志条目。
正常的情况下,领导人和跟随者的日志保持一致,附加日志RPC都能成功返回。但是,领导人的崩溃会使得日志处于不一致的状态,跟随者可能丢失一些在新领导人中存在的日志,也可能会多出一些新领导人中没有的日志。
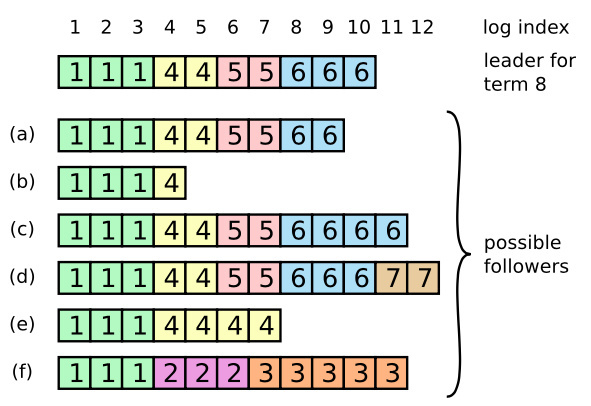
Raft算法中,日志是与领导人的日志强制保持一致的,也就是说,跟随者中不一致的日志会被领导人的日志覆盖。这也是通过附加日志rpc完成的。
- 领导人针对每一个跟随者都维护了一个nextIndex,表示下一个需要发送给这个跟随者的日志条目的索引位置。一个领导人刚选举出来的时候,所有的nextIndex都初始化为自己的最后一条日志+1。
- 如果日志不一致,那么附加日志RPC的一致性检查就会失败
- 领导人减小nextIndex进行重试,直到在某个位置附加日志RPC成功,说明日志达成一致。
- 跟随者把冲突的日志条目全部删除并且加上领导人日志,附加日志RPC成功,跟随者与领导人的日志保持一致。
安全性
为了保证描述的机制能够正确执行,还需要添加一些限制。例如在日志复制中,一个跟随者进入不可用状态同时领导人提交了若干日志,随后这个跟随者被选为领导人会覆盖掉之前提交的日志。
因此在选举领导人的时候需要添加限制,要挑选日志比较完善的节点作为领导人。这就是领导人完整特性(Leader Completeness Property),即任何领导人对于给定的任期号,都拥有之前任期的所有被提交的日志条目。
选举限制
任何基于领导人的一致性算法中,领导人都必须存储所有已提交的日志条目。
Raft算法采取投票的方式来阻止不满足要求的候选人赢得选举。在请求投票RPC中包含了候选人的日志信息,投票人会拒绝掉那些日志没有自己新的投票请求。
因为候选人赢得选举需要获得大部分选票,而之前的领导人要提交一个日志必须将这个日志复制到大多数节点上,所以如果这个候选人与大多数节点的日志一样新,那么它一定包含所有已提交的日志,这样就能够保证新的领导人一定具有全部已提交的日志。
日志的比较方式如下:
- 任期号大的日志比较新。
- 任期号相同的话,比较长的日志要新。
提交之前任期的日志条目
下图展示了一种情况,一条已经被存储到大多数节点上的老日志条目,也依然有可能会被未来的领导人覆盖掉。
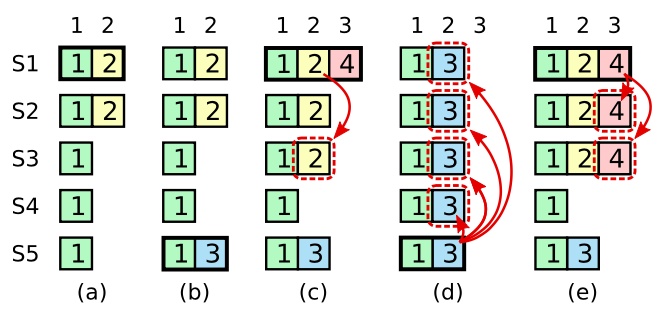
如图的时间序列展示了为什么领导人无法决定对老任期号的日志条目进行提交。在 (a) 中,S1 是领导人,部分的(跟随者)复制了索引位置 2 的日志条目。在 (b) 中,S1 崩溃了,然后 S5 在任期 3 里通过 S3、S4 和自己的选票赢得选举,然后从客户端接收了一条不一样的日志条目放在了索引 2 处。然后到 (c),S5 又崩溃了;S1 重新启动,选举成功,开始复制日志。在这时,来自任期 2 的那条日志已经被复制到了集群中的大多数机器上,但是还没有被提交。如果 S1 在 (d) 中又崩溃了,S5 可以重新被选举成功(通过来自 S2,S3 和 S4 的选票),然后覆盖了他们在索引 2 处的日志。反之,如果在崩溃之前,S1 把自己主导的新任期里产生的日志条目复制到了大多数机器上,就如 (e) 中那样,那么在后面任期里面这些新的日志条目就会被提交(因为 S5 就不可能选举成功)。 这样在同一时刻就同时保证了,之前的所有老的日志条目就会被提交。
上述问题出现的根本原因在于,新的任期复制提交旧的任期的日志,导致虽然大多数节点都复制了旧的任期日志,但是并不能保证大多数节点的日志就是最新的,让已提交的日志被覆盖。
为了消除这种情况,Raft 永远不会通过计算副本数目的方式去提交一个之前任期内的日志条目。只有领导人当前任期里的日志条目通过计算副本数目可以被提交;一旦当前任期的日志条目以这种方式被提交,那么由于日志匹配特性,之前的日志条目也都会被间接的提交。
跟随者和候选人崩溃
跟随者和候选人崩溃的处理方式是很简单的,就是简单地无限的重试;机器重启了就会成功响应。 因为Raft的RPC都具有幂等性,所以重试不会造成任何问题。
时间和可用性
Raft的要求之一就是安全性不能依赖时间,但是可用性不可避免地要依赖时间。
Raft需要选举并维持一个稳定地领导人,需要系统满足以下要求:
广播时间(broadcastTime) << 选举超时时间 (electionTimeout) << 平均时间故障(MTBF)
- 广播时间:一个服务器并行发送RPC给其它服务器并接收响应地平均时间。
- 选举超时时间:接收心跳的最长时间范围。
- 平均故障时间:一个服务器两次故障之间的平均时间。
广播时间要比选举超时时间小一个量级,这样领导人才能发送稳定的心跳。选举超时时间要比平均故障时间小几个数量级,这样真个系统才能稳定运行。
广播时间和平均故障时间是由系统决定的,而选举超时间是可以自己决定的。Raft的rpc广播时间大约在0.5毫秒到20毫秒之间,取决于存储的技术。因此选举超时时间可能需要在10毫秒到500毫秒之间。
集群成员变更
在实践中,偶尔是会改变集群的配置的,Raft提供了自动化配置改变来让集群不停止变更配置。
但是存在这样一个问题,服务器的配置从旧到新变更这个过程我们无法保证所有的服务器同时完成,那么就存在这样一个时间点,两个不同的领导人在同一个任期里都可以被选举成功。一个是通过旧的配置,一个通过新的配置。
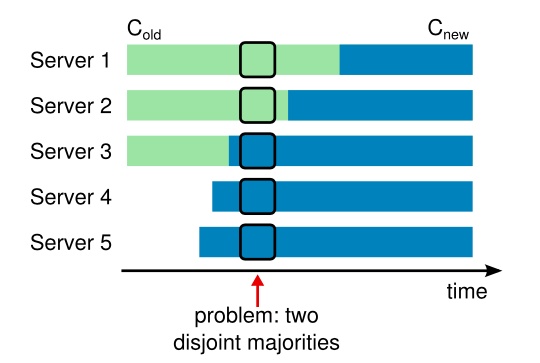 为了保证安全性,配置变更采用两阶段方法。在Raft中,集群先切换到一个过渡的配置,称之为共同一致(joint consensus);一旦共同一致提交了,系统就切换到新的配置上。
为了保证安全性,配置变更采用两阶段方法。在Raft中,集群先切换到一个过渡的配置,称之为共同一致(joint consensus);一旦共同一致提交了,系统就切换到新的配置上。
共同一致是老配置和新配置的结合:
- 日志条目被复制给集群中新、老的所有服务器
- 新、旧配置的服务器都可以成为领导人
- 达成一致(选举和提交)需要分别在两种配置上获得大多数支持
共同一致允许独立的服务器在不影响安全性的前提下,在不同的时间进行配置转换过程。此外,共同一致可以让集群在配置转换的过程中依然响应客户端的请求。
集群配置在复制日志中以特殊的日志条目来存储和通信
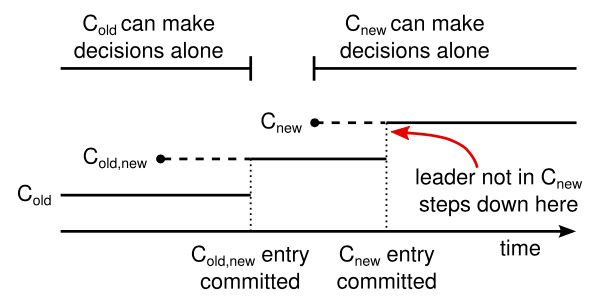
一个配置切换的时间线。虚线表示已经被创建但是还没有被提交的配置日志条目,实线表示最后被提交的配置日志条目。领导人首先创建了 C-old,new 的配置条目在自己的日志中,并提交到 C-old,new 中(C-old 的大多数和 C-new 的大多数)。然后他创建 C-new 条目并提交到 C-new 中的大多数。这样就不存在 C-new 和 C-old 可以同时做出决定的时间点。
当一个领导人接收到一个改变配置从 C-old 到 C-new 的请求,他会为了共同一致存储配置(图中的 C-old,new),以前面描述的日志条目和副本的形式。一旦一个服务器将新的配置日志条目增加到它的日志中,他就会用这个配置来做出未来所有的决定(服务器总是使用最新的配置,无论他是否已经被提交)。
一旦 C-old,new 被提交,那么无论是 C-old 还是 C-new,如果不经过另一个配置的允许都不能单独做出决定,并且领导人完全特性保证了只有拥有 C-old,new 日志条目的服务器才有可能被选举为领导人。这个时候,领导人创建一条关于 C-new 配置的日志条目并复制给集群就是安全的了。再者,每个服务器在见到新的配置的时候就会立即生效。当新的配置在 C-new 的规则下被提交,旧的配置就变得无关紧要,同时不使用新的配置的服务器就可以被关闭了.C-old 和 C-new 没有任何机会同时做出单方面的决定;这保证了安全性。
重新配置还有三个问题:
- 新的服务器加入集群的时候可能初始化没有任何日志。它们需要一段时间来更新追赶,Raft在配置更新之前使用了一个额外的阶段,在这个阶段,新的服务器以没有投票权的身份加入到集群中来(领导人复制日志给它们,但是不考虑它们是大多数)。一旦追平,重新配置可以按照上面描述的处理。
- 集群的领导人可能不是新配置的一员。在这种情况下,领导人就会在提交了 C-new 日志之后退位(回到跟随者状态)。这意味着有这样的一段时间,领导人管理着集群,但是不包括他自己;他复制日志但是不把他自己算作是大多数之一。当 C-new 被提交时,会发生领导人过渡,因为这时是最早新的配置可以独立工作的时间点(将总是能够在 C-new 配置下选出新的领导人)。在此之前,可能只能从 C-old 中选出领导人。
- 第三个问题是,移除不在 C-new 中的服务器可能会扰乱集群。这些服务器将不会再接收到心跳,所以当选举超时,他们就会进行新的选举过程。他们会发送拥有新的任期号的请求投票 RPCs,这样会导致当前的领导人回退成跟随者状态。新的领导人最终会被选出来,但是被移除的服务器将会再次超时,然后这个过程会再次重复,导致整体可用性大幅降低。
为了避免这个问题,当服务器确认当前领导人存在时,服务器会忽略请求投票 RPCs。特别的,当服务器在当前最小选举超时时间内收到一个请求投票 RPC,他不会更新当前的任期号或者投出选票。这不会影响正常的选举,每个服务器在开始一次选举之前,至少等待一个最小选举超时时间。然而,这有利于避免被移除的服务器扰乱:如果领导人能够发送心跳给集群,那么他就不会被更大的任期号废黜。
日志压缩
在实际使用中,日志是不可能无限制增长的,需要有一定的机制请求日志里积累的陈旧的信息。
快照是最简单的办法。将某个时间点系统的状态以快照的形式写入持久化存储中,然后将那个是时间点之前的日志全部丢弃。
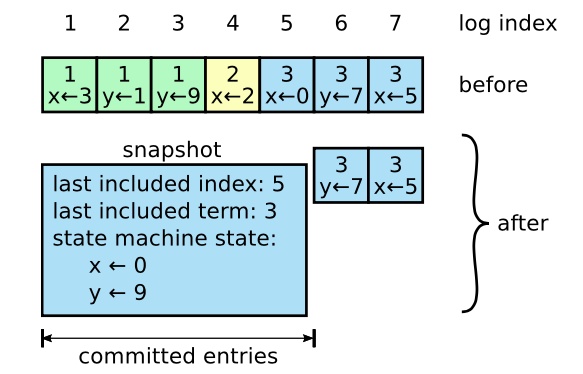
一个服务器用新的快照替换了从 1 到 5 的条目,快照值存储了当前的状态。快照中包含了最后的索引位置和任期号。
每个服务器独立创建快照,只包括已提交的日志。主要工作包括将状态机的状态写入快照中,还有一些元数据:last included index,last included term是为了支持快照后紧接着的第一条日志条目的附加日志RPC的一致性检查。
虽然快照是独立创建的,但是有时候领导人需要将快照发送给一些落后的跟随者,例如运行速度慢的跟随者或者新加入的服务器。
这正是前面所说的第三种RPC。安装快照RPC。由领导人调用将快照的分块发送给跟随者。
| 参数 | 解释 |
|---|---|
| term | 领导人的任期号 |
| leaderId | 领导人的ID,以便于跟随者重定向请求 |
| lastIncludedIndex | 快照中包含的最后日志条目的索引值 |
| lastIncludedTerm | 快照中包含的最后日志条目的任期号 |
| offset | 分块在快照中的字节偏移量 |
| data[] | 从偏移量开始的快照分块的原始字节 |
| done | 如果这是最后一个分块则为true |
| 结果 | 解释 |
|---|---|
| term | 当前任期号(currentTerm),便于领导人更新自己 |
接收者实现:
- 如果
term < currentTerm就立即回复 - 如果是第一个分块(offset 为 0)就创建一个新的快照
- 在指定偏移量写入数据
- 如果 done 是 false,则继续等待更多的数据
- 保存快照文件,丢弃具有较小索引的任何现有或部分快照
- 如果现存的日志条目与快照中最后包含的日志条目具有相同的索引值和任期号,则保留其后的日志条目并进行回复
- 丢弃整个日志
- 使用快照重置状态机(并加载快照的集群配置)
客户端交互
Raft 中的客户端发送所有请求给领导人。当客户端启动的时候,他会随机挑选一个服务器进行通信。如果客户端第一次挑选的服务器不是领导人,那么那个服务器会拒绝客户端的请求并且提供他最近接收到的领导人的信息(附加条目请求包含了领导人的网络地址)。如果领导人已经崩溃了,那么客户端的请求就会超时;客户端之后会再次重试随机挑选服务器的过程。
Raft 的目标是要实现线性化语义(每一次操作立即执行,只执行一次,在他调用和收到回复之间)。但是,如上述,Raft 是可能执行同一条命令多次的:例如,如果领导人在提交了这条日志之后,但是在响应客户端之前崩溃了,那么客户端会和新的领导人重试这条指令,导致这条命令就被再次执行了。解决方案就是客户端对于每一条指令都赋予一个唯一的序列号。然后,状态机跟踪每条指令最新的序列号和相应的响应。如果接收到一条指令,它的序列号已经被执行了,那么就立即返回结果,而不重新执行指令。
只读的操作可以直接处理而不需要记录日志。但是,在不增加任何限制的情况下,这么做可能会冒着返回脏数据的风险,因为响应客户端请求的领导人可能在他不知道的时候已经被新的领导人取代了。线性化的读操作必须不能返回脏数据,Raft 需要使用两个额外的措施在不使用日志的情况下保证这一点。首先,领导人必须有关于被提交日志的最新信息。领导人完全特性保证了领导人一定拥有所有已经被提交的日志条目,但是在他任期开始的时候,他可能不知道哪些是已经被提交的。为了知道这些信息,他需要在他的任期里提交一条日志条目。Raft 中通过领导人在任期开始的时候提交一个空白的没有任何操作的日志条目到日志中去来实现。第二,领导人在处理只读的请求之前必须检查自己是否已经被废黜了(他自己的信息已经变脏了如果一个更新的领导人被选举出来)。Raft 中通过让领导人在响应只读请求之前,先和集群中的大多数节点交换一次心跳信息来处理这个问题。可选的,领导人可以依赖心跳机制来实现一种租约的机制,但是这种方法依赖时间来保证安全性(假设时间误差是有界的)。
hashicorp实现
首先看入口函数,这里是在raft.go下的run()中,
func (r *Raft) run() {
for {
select {
case <-r.shutdownCh:
r.setLeader("", "")
return
default:
}
switch r.getState() {
case Follower:
r.runFollower()
case Candidate:
r.runCandidate()
case Leader:
r.runLeader()
}
}
}整个服务器运行的逻辑就是,在一个死循环中,如果检测到程序结束就退出程序;否则就根据服务器的角色来运行对应的函数。
接下来便从Raft算法的三个模块开始介绍三个功能。
领导者选举
跟随者如何发起请求
跟随者设置了一个随机选举超时时间,如果在超时时间内没有收到消息,那么会变为候选人,发起选举。
在runFollow()函数中的对应代码如下:
func (r *Raft) runFollower() {
heartbeatTimer := randomTimeout(r.config().HeartbeatTimeout)
for r.getState() == Follower {
select {
...
case <-heartbeatTimer:
//超时处理
...
}
}
}首先创建了一个定时器timer:
// 随机超时时间在[minVal, 2 * minVal)中
func randomTimeout(minVal time.Duration) <-chan time.Time {
if minVal == 0 {
return nil
}
extra := time.Duration(rand.Int63()) % minVal
return time.After(minVal + extra)
}这里需要注意,定时器超时并不代表着心跳超时,因为定时器在创建完成之后就开始计时,触发一次就结束。所以通过lastContact记录着上一次通信的时间,用时间差来表示是否超时。心跳定时器是为了定时触发检测的。
case <-heartbeatTimer:
// 重启心跳定时器
hbTimeout := r.config().HeartbeatTimeout
heartbeatTimer = randomTimeout(hbTimeout)
// 检查是否超时
lastContact := r.LastContact()
if time.Now().Sub(lastContact) < hbTimeout {
continue
}
}
如果超时才会继续往下走。变成候选人,发起选举。内部还有一些额外的处理,这里就忽略
r.setState(Candidate)
return设置为候选人状态,退出函数,那么就重新回到了run()的for循环当中,只是接下来调用的就是runCandidate()函数了。
候选人如何接收请求
候选人将自己的任期号加1,并行发起请求投票RPC,获得过半选票才能赢得选举。同样有一个选举时间,如果超时时间内有其它候选人赢得选举,那么重新成为跟随者,如果超时也没有领导人产生,那么就发起新一轮选举。 先看整体流程:
func (r *Raft) runCandidate() {
// 开始选举,并设置超时。投票的结果都放入voteCh中
voteCh := r.electSelf()
//随机选举定时器
electionTimeout := r.config().ElectionTimeout
electionTimer := randomTimeout(electionTimeout)
//获得的选票数
grantedVotes := 0
//赢得选举需要的最小票数
votesNeeded := r.quorumSize()
for r.getState() == Candidate {
select {
case vote := <-voteCh:
//投票结果的处理
case <-electionTimer:
//选举失败,退出重新选举
r.logger.Warn("Election timeout reached, restarting election")
return
}
}
}可以看出处理流程如下:
- 发起选举。由
electSelf()函数处理。 - 设置选举超时定时器。
- 进入循环
- 从voteCh中获得投票结果并处理。
- 选举超时,说明选举失败,开始下一轮选举。
这里先说明以下第4步的处理方式:
case vote := <-voteCh:
// 1.如果存在比自己任期号更大的服务器,那么变回跟随者,并将自己的任期号设置为较大的任期号
if vote.Term > r.getCurrentTerm() {
r.setState(Follower)
r.setCurrentTerm(vote.Term)
return
}
// 2.如果获得选票,则选票票数加1。
if vote.Granted {
grantedVotes++
}
// 3.如果票数达到要求,则变成领导人
if grantedVotes >= votesNeeded {
r.setState(Leader)
r.setLeader(r.localAddr, r.localID)
return
}那么接下来便是electSelf()函数的实现了,其功能我们都很清楚,就是并行发起RequestVote RPC,获得选票。
func (r *Raft) electSelf() <-chan *voteResult {
// 创建一个通道,存放投票的结果
respCh := make(chan *voteResult, len(r.configurations.latest.Servers))
// 当前任期号自增
r.setCurrentTerm(r.getCurrentTerm() + 1)
//构造请求
lastIdx, lastTerm := r.getLastEntry()
req := &RequestVoteRequest{
RPCHeader: r.getRPCHeader(),
Term: r.getCurrentTerm(),
// this is needed for retro compatibility, before RPCHeader.Addr was added
Candidate: r.trans.EncodePeer(r.localID, r.localAddr),
LastLogIndex: lastIdx,
LastLogTerm: lastTerm,
LeadershipTransfer: r.candidateFromLeadershipTransfer,
}
// 构造请求投票的函数。
askPeer := func(peer Server) {
// goFunc是一个辅助函数,用来进行同步的
r.goFunc(func() {
defer metrics.MeasureSince([]string{"raft", "candidate", "electSelf"}, time.Now())
resp := &voteResult{voterID: peer.ID}
err := r.trans.RequestVote(peer.ID, peer.Address, req, &resp.RequestVoteResponse)
if err != nil {
resp.Term = req.Term
resp.Granted = false
}
respCh <- resp
})
}
// 对每一个节点请求一次投票
for _, server := range r.configurations.latest.Servers {
if server.Suffrage == Voter {
if server.ID == r.localID {
// Persist a vote for ourselves
if err := r.persistVote(req.Term, req.RPCHeader.Addr); err != nil {
r.logger.Error("failed to persist vote", "error", err)
return nil
}
// 自己给自己一个投票
respCh <- &voteResult{
RequestVoteResponse: RequestVoteResponse{
RPCHeader: r.getRPCHeader(),
Term: req.Term,
Granted: true,
},
voterID: r.localID,
}
} else {
askPeer(server)
}
}
}
return respCh
}实现思路非常明确了:
- 创建一个通道respCh用以存入请求投票RPC的结果。
- 构造请求投票RPC的请求参数RequestVoteRequest。
- 循环遍历每一个服务器节点,对它们发起请求投票RPC,注意如果是自身节点的话,直接往respCh中写入结果就行。RPC调用结果写入respCh。
askPeer是一个辅助函数,同时帮助进行同步
func (r *raftState) goFunc(f func()) {
r.routinesGroup.Add(1)
go func() {
defer r.routinesGroup.Done()
f()
}()
}在领导人选举这个过程中涉及请求投票RPC,接下来就了解一下请求投票RPC。
请求投票RPC的工程实现
在这个项目中,使用transport接口来通信。相关的RPC请求的接口也在这里。
transport分别有用作内存测试的,无需网络通信的InmemTransport实现和需要网络通信的NetworkTransport实现,这里只关心NetworkTransport。
在commands.go下定义了参数的数据类型:
请求参数RequestVoteRequest如下:
type RPCHeader struct {
// 其中,ProtocolVersion为发送端使用的协议版本。
ProtocolVersion ProtocolVersion
// ID是发送RPC请求或响应的节点的ServerID
ID []byte
// Addr为发送RPC请求或响应的节点的ServerAddr
Addr []byte
}
type RequestVoteRequest struct {
RPCHeader
// Provide the term and our id
Term uint64
// 过期字段,用RPCHeader.Addr替代
Candidate []byte
// 用来确保安全,也就是确保领导人完整性
LastLogIndex uint64
LastLogTerm uint64
//用于向其它节点表明这次投票是否是由领导人变更引起的。这是领导人变更生效的必要条件,因为如果服务器知道现有的领导,他们不会投票的。
LeadershipTransfer bool
}响应参数RequestVoteResponse如下:
type RequestVoteResponse struct {
RPCHeader
// Newer term if leader is out of date.
Term uint64
// 这是一个过期字段,但是如果对端协议版本是0的话,需要使用此字段。协议版本大于等于2的不需要此字段。
Peers []byte
// 是否获得选票
Granted bool
}对应于NetworkTransport的实现,调用了NetworkTransport的genericRPC函数。
func (n *NetworkTransport) genericRPC(id ServerID, target ServerAddress, rpcType uint8, args interface{}, resp interface{}) error {
// 获取连接
conn, err := n.getConnFromAddressProvider(id, target)
if err != nil {
return err
}
// 设置deadline也就是超时时间
if n.timeout > 0 {
conn.conn.SetDeadline(time.Now().Add(n.timeout))
}
// 发送RPC
if err = sendRPC(conn, rpcType, args); err != nil {
return err
}
// 解码响应
canReturn, err := decodeResponse(conn, resp)
if canReturn {
n.returnConn(conn)
}
return err
}sendRPC根据rpc的类型来封装请求,decodeResponse用来解析响应。这里我们不需要关注,我们主要关注接收方的实现。
handleConn为连接的处理函数,其中调用的handleCommand是我们需要关注的具体实现,它会根据rpc请求的类型来进行对应的处理,这里我们只关注请求投票的处理方式
func (n *NetworkTransport) handleCommand(r *bufio.Reader, dec *codec.Decoder, enc *codec.Encoder) error {
// Get the rpc type
rpcType, err := r.ReadByte()
// Create the RPC object
respCh := make(chan RPCResponse, 1)
rpc := RPC{
RespChan: respCh,
}
switch rpcType {
case rpcRequestVote:
var req RequestVoteRequest
if err := dec.Decode(&req); err != nil {
return err
}
rpc.Command = &req
}
// Dispatch the RPC,这样处理协程就能够从consumeCh中取出rpc并处理,调用结果写入rpc的respCh中。
select {
case n.consumeCh <- rpc:
case <-n.shutdownCh:
return ErrTransportShutdown
}
select {
// 处理响应
case resp := <-respCh:
// Send the error first
respErr := ""
if resp.Error != nil {
respErr = resp.Error.Error()
}
if err := enc.Encode(respErr); err != nil {
return err
}
// Send the response
if err := enc.Encode(resp.Response); err != nil {
return err
}
case <-n.shutdownCh:
return ErrTransportShutdown
}
关键在这里将rpc写入了NetworkTransport的consumeCh中,我们要了解NetworkTransport是如何取出rpc并处理,将结果写入rpc的respCh的。
在NetworkTransport类型中有一个成员consumerCh的RPC通道
type NetworkTransport struct {
...
consumeCh chan RPC
...
}在raft.go文件的类型Raft中存在一个成员变量rpcCh <-chan RPC,这个类型正是来自NetworkTransport的consumerCh。
type Raft struct {
...
rpcCh <- chan RPC
...
}Raft的processRPC正是用来处理接收到的RPC的。我们将这个流程清晰一下
Note
这里使用
NetworkTransport的网络通信来分析
发送端
服务器之间的网络请求都通过NetworkTransport来实现,而服务器节点之间的RPC调用最终都通过它的genericRPC函数统一处理。
发送端的处理流程如下:
- 调用
sendRPC函数来根据RPC类型和请求数据封装成统一的数据包进行发送。 - 调用
decodeResponse获取读取数据包并解码。 发送端比较简单,关键是接收端的处理。
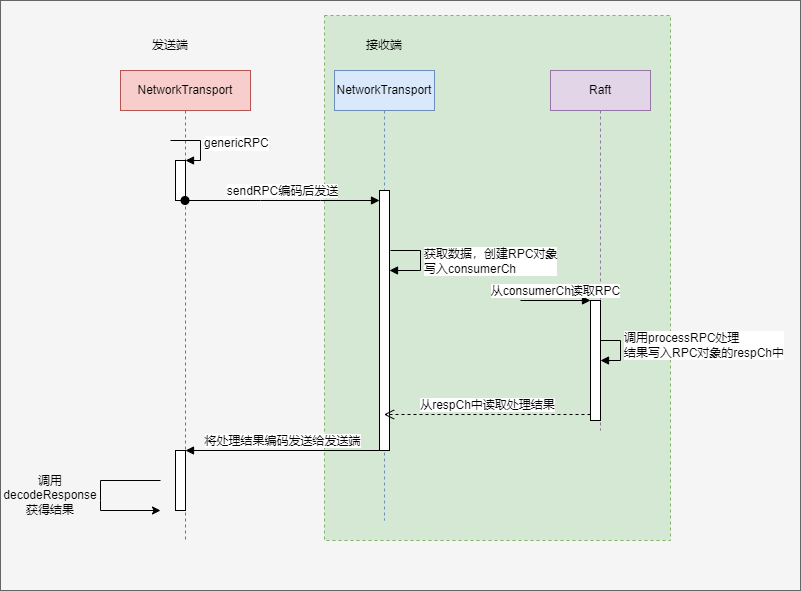
接收端
从NetworkTransport的listen中我们可以看到,对于每一个连接,都启动一个协程调用handleConn进行处理。
在handleConn中启动一个循环,不断调用handleCommand函数来处理一个个数据包。而handleCommand的流程如下:
- 先读取rpc的类型头
- 创建一个RPC数据类型的对象,并包含一个成员
respCh,由RPC的处理者将处理的结果写入这个通道。 - 根据RPC的类型,来解码出对应的数据,将需要的数据准备好都存入上一步创建的RPC对象。
- 将RPC对象写入
NetworkTransport实例的consumerCh中。 - 由RPC调用的具体实现者
Raft的processRPC取出RPC对象进行处理,并将结果写入RPC对象的respCh通道中。 - 从
respCh中读取处理结果,编码成数据发送给发送端。
 我们最后了解
我们最后了解Raft的processRPC对请求投票的RPC的具体实现逻辑流程对应于Raft类型的requestVote函数,其核心逻辑如下:
- 如果请求中包含的任期号term比当前的要小,那么忽略这个请求。
- 如果请求中包含的任期号要比当前节点的要新,那么当前节点变更为跟随者,任期号变为较新的任期号。
- 获取最新一次投票的任期号和最新一次投票的候选人信息。因为一个任期内只能对一个候选人投票,所以如果当前任期这个节点已经投过票了,那么就直接结束,没有则继续往下执行。
- 将请求中的日志条目与本节点的日志条目比较,如果没有本节点的日志条目新(任期号大,索引号大),那么就拒绝,否则继续执行。
- 执行到这里说明能够成功投票,将这次投票的任期和候选人的信息记录下来,作为下一次处理中判断是否投票的依据。 对应代码如下:
// 如果是过期请求直接拒绝
if req.Term < r.getCurrentTerm() {
return
}
if req.Term > r.getCurrentTerm() {
// 遇到任期号更大的请求,当前节点直接变更为跟随者,任期号设置为新的任期号
r.setState(Follower)
r.setCurrentTerm(req.Term)
resp.Term = req.Term
}
// 获取最新一次投票的任期和其投票的候选人
lastVoteTerm, err := r.stable.GetUint64(keyLastVoteTerm)
lastVoteCandBytes, err := r.stable.Get(keyLastVoteCand)
// 如果这个任期投过票,那么就不投票了
if lastVoteTerm == req.Term && lastVoteCandBytes != nil {
return
}
//当前最新的日志条目的任期号和索引号。
lastIdx, lastTerm := r.getLastEntry()
// 如果本节点的日志要更新,那么就拒绝为这个候选人投票
if lastTerm > req.LastLogTerm {
return
}
if lastTerm == req.LastLogTerm && lastIdx > req.LastLogIndex {
return
}
// 将本次投票记作最新一次投票,并投票成功
r.persistVote(req.Term, candidateBytes)
resp.Granted = true至此,领导人选举的requestRPC流程说明完毕。
日志复制
Raft算法日志由领导人复制给其它节点。也就是说,领导人作为发送端,跟随者和候选人作为接收端。
领导人如何发起日志复制请求
在raft.go下的runLeader()为领导人的执行逻辑。
- 准备好领导人的状态数据。
- 根据配置文件和领导人的状态来建立未建立的连接和关闭不必要的连接,并为每一个连接启动一个协程负责日志复制的工作。
- 先提交一个空日志,这是为了这个刚成为领导人的节点确保自己的数据都是已提交的。
- 进入领导人的循环当中,不断获取请求并处理。 大致流程对应的代码如下:
func (r *Raft) runLeader() {
// 设置数据
r.setupLeaderState()
// 为每一个节点启动一个复制协程
r.startStopReplication()
// 提交一个空日志确保自己的所有日志都是已提交的
noop := &logFuture{log: Log{Type: LogNoop}}
r.dispatchLogs([]*logFuture{noop})
// 进入循环处理中
r.leaderLoop()
}接下来了解一下日志复制协程的启动startStopReplication:
- 获取配置文件中的服务器节点。
- 遍历节点判断是否在领导人的记录当中。
- 如果在并且更新了节点的信息,那么就进行更新。
- 如果不在,那么便为这个节点启动一个日志复制协程。
func (r *Raft) startStopReplication() {
for _, server := range r.configurations.latest.Servers {
if server.ID == r.localID {
continue
}
// 判断配置中的节点是否已经建立连接
s, ok := r.leaderState.replState[server.ID]
if !ok {
// 没有则建立连接
r.goFunc(func() { r.replicate(s) })
} else if ok {
// 由则判断是否需要更新
}
}replicate函数很明显就是每隔一段时间就发送一次日志复制请求:
select {
case <-randomTimeout(r.config().CommitTimeout):
lastLogIdx, _ := r.getLastLog()
shouldStop = r.replicateTo(s, lastLogIdx)
}
}到这里,我们基本可以确定,日志复制请求就是在replicateTo函数中调用的:
- 构造日志复制请求
- 发送RPC请求。(这里与领导者选举中提到的发送过程一样)
- 如果响应的节点的任期号比领导人的任期号还要新,那么说明这个领导人过期了,停止对所有节点的日志复制RPC的发送,退出领导人执行。
- 如果请求成功则对应的nextIndex+1,失败则对应的nextIndex-1。
接收端如何响应日志复制请求
也是在Raft的processRPC中处理这个RPC请求。判断出请求类型之后,对于日志复制就调用appendEntries函数进行对应的处理。
- 请求中的任期号比当前节点的任期号小,则忽略这个rpc请求。
- 如果请求中的任期号比当前节点的大,那么当前节点状态就变更为跟随者,任期号设置为较大的任期号。
- 根据请求中的日志条目的索引找到本节点对应的日志,比较两者的任期号是否相同。只有索引和任期都相同的日志条目才相同,不相同,则这次日志复制失败。相同则继续。
- 将本节点中与请求中的日志条目冲突的地方全部删除,以请求中的日志条目为主(以领导人日志为主)。
- 将新日志扩展进入。
- 根据请求中的已提交索引和本节点的最新日志索引来提交本节点的日志。